O cérebro ainda é um grande mistério para a ciência e guarda muitos segredos, mas apesar desse conhecimento limitado foram feitos grandes esforços para tentar imitar o comportamento do cérebro usando computadores, o que resultou nas Redes Neurais Artificiais.
As Redes Neurais (ou Neuronais) têm uma longa história, quase tão longa quanto a do próprio computador.
As Redes Neurais Artificiais são programas de computador baseados em um modelo simplificado do cérebro. Elas não tentam reproduzir em detalhes o funcionamento do cérebro, mas tentam reproduzir sua operação lógica usando uma coleção de entidades análogas aos neurônios para executar o processamento.
O neurônio é uma célula altamente especializada que funciona como a unidade de processamento fundamental no cérebro (Figura Z.1). Um cérebro humano típico tem aproximadamente 8,6x1010 (86 bilhões) de neurônios, e representam aproximandamente 50% do total da massa cerebral (Journal of Comparative Neurology).
Figura Z.1. Modelo simplificado de um neurônio (Fonte: Applications of artificial intelligence in chemistry, 1993)
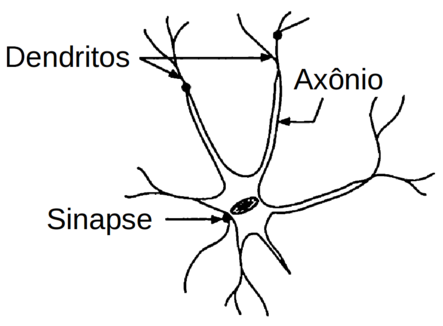
Cada neurônio pode estar conectado a até 10.000 outros neurônios, passando sinais uns aos outros através das conexões sinápticas.
A bioquímica detalhada que ocorre ao nível molecular nos neurônios não é inteiramente compreendida, mas o padrão básico de comportamento é conhecido.
Os sinais elétricos chegam constantemente nos neurônios através dos dendritos, e são processados pelo neurônio de uma forma que se assemelha ao funcionamento de um pequeno dispositivo lógico. Os sinais canalizados para o neurônio durante um curto período de tempo são integrados ou somados bioquimicamente. E se a soma destes sinais atinge um certo nível, o neurônio assume um estado “excitado”, após o que ele transmite um sinal para outros neurônios através do axônio.
Devido à estrutura altamente ramificada dos dendritos, uma única mensagem de saída do neurônio é dividida muitas vezes e é transmitida para vários outros neurônios.
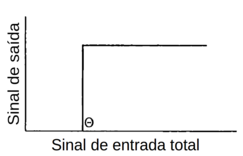
O neurônio permanece quiescente (em repouso, não excitado) enquanto a soma dos sinais de entrada durante um período de tempo estiver abaixo de alguma tensão crítica (em Inglês: threshold). Se a tensão de limiar (tensão crítica - threshold) é excedida, o neurônio é ligado e um sinal de saída é gerado.
Esta tensão limite é determinada por uma função de limiar que tem uma forma escalonada e é conhecida como função degrau ou Função de Heaviside (Figura Z.2).
Figura Z.2. Função de limiar Heaviside (Fonte: Applications of artificial intelligence in chemistry, 1993)
Os neurônios passam rapidamente do estado excitado para o estado de repouso, mas o sinal gerado pode ter desencadeado uma ação em muitos outros neurônios em outra parte da rede. Devido à complexidade da interconexão neuronal, os sinais se propagam através de uma rede tridimensional no cérebro de uma forma extremamente complexa.
A rede está constantemente ativa com sinais sendo transmitidas de neurônio para neurônio, e os neurônios retornando sinais para os músculos ou recebendo sinais dos nossos sentidos estimulados pelo ambiente externo. Toda essa atividade incessante é fundamental como “base” para o pensamento e para a aprendizagem.
As conexões entre os neurônios pelas quais trafegam mensagens frequentes são fortalecidas pela repetição dos estímulos e dessa forma essas conexões são reforçadas ao longo do tempo. Este reforço preferencial das ligações mais usadas de uma rede neuronal, ocorre à medida que dominamos um novo conhecimento ou habilidade, e isso parece ser um dos componentes do processo de aprendizagem. E é exatamente esse mecanismo que se busca reproduzir em uma rede neural artificial.
“Redes Neurais Artificiais” são modelos computacionais que apresentam um modelo matemático inspirado na estrutura neural de organismos inteligentes e que adquirem conhecimento através da experiência. (Fonte: Redes Neurais Artificiais - ICMC/USP)
Como vimos, o mecanismo de funcionamento de uma rede neural é baseada na “aprendizagem por reforço” com repetição dos estímulos.
Por isso podemos destacar duas características importantes das redes neurais:
Não é necessário para uma rede neural indicar o caminho que deve ser seguido para a resolução de um problema
As redes neurais são ferramentas “multipropósito”, ou seja, com o devido treinamento, um único programa poderia resolver diferentes problemas de interpretação espectral, lógica proposicional ou análise de imagem.
Essas são características bem diferentes do tradicional paradigma da Programação Imperativa na qual um programa é concebida para realizar uma tarefa específica executando comandos predefinidos.
Um neurônio é uma entidade complexa cuja transmissão de sinais se baseia na mobilidade de íons através da membrana. Com base em complexos mecanismos ele é capaz de detectar e somar os pequenos sinais de entrada, avaliar a intensidade do sinal resultante e transmitir sinais para outros neurônios.
Mas embora a bioquímica interna que realiza essas operações seja bastante complexa as operações lógicas e matemáticas realizadas são simples e podem ser resumidas em três funções:
Um neurônio tem múltiplas conexões de entrada e, de alguma forma, pode adicionar os sinais que chegam a essas conexões.
Se a soma das entradas está abaixo de um valor limite, o neurônio permanece desativado. E se a soma atinge o nível limite, o neurônio é ativado e uma mensagem é enviada.
O neurônio retorna a um estado de repouso após um curto período de tempo.
É relativamente simples simular em um computador um neurônio artificial com essas características. E esse “neurônio artificial” é conhecido como “perceptron elementar” (Figura Z.3).
Figura Z.3. Um perceptron elementar é um sistema de “alimentação direta” (feedforward) no qual os sinais de entrada são processados e alimentam uma saída em uma única direção (sem realimentação, retroalimentação ou loop) (Fonte: Applications of artificial intelligence in chemistry, 1993)
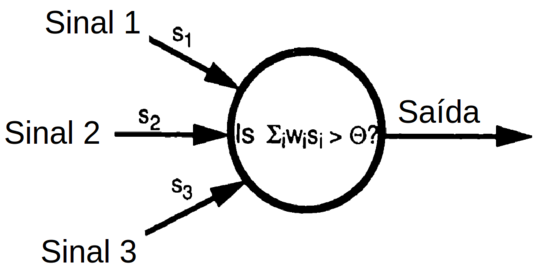
O perceptron é um sistema de alimentação direta muito simples mas que ainda assim pode aprender a executar algumas tarefas úteis. O perceptron representa o “bloco elementar de construção” com o qual as redes neurais artificiais são construídas.
Como funciona o “aprendizado” de um perceptron?
O perceptron é uma unidade de tomada de decisão com várias conexões de entrada (também conhecidas como sinapses por analogia com o neurônio) e uma única conexão de saída. Um sinal de entrada si é multiplicado pelo “peso da conexão” wi de modo que cada sinal aparece no perceptron como um valor ponderado wisi. O perceptron soma os sinais de entrada para dar um sinal total S = ∑i wisi.
O perceptron aplica então uma função de limiar de ativação, por exemplo a Função de Heaviside (Figura Z.2), com limiar de ativação 8 (Θ = 8)para a soma dos sinais de entrada ponderados S. Se a soma S atinge o limiar de ativação o perceptron é “ativado”, e se a soma S ficar abaixo deste nível o perceptron permanece em repouso.
Entrada (Input) = ∑i wisi
Saída (Output) = 1 Se (If) ∑i wisi ≥ Θ
Saída (Output) = 0 Se (If) ∑i wisi < Θ
O comportamento de um perceptron é determinado pelos pesos das conexões dos sinais de entrada e pelo limiar de ativação definido.
O “conhecimento armazenado” corresponde aos “valores dos pesos” de tal forma que um perceptron que “não sabe nada” é incializado os pesos de conexão “aleatórios”. O processo de “aprendizagem” ou “treinamento” consiste no ajuste dos pesos de uma forma análoga ao treinamento de um sistema biológico. Através de uma modificação gradual dos pesos, o perceptron pode “apender” a executar diversos cálculos.
O processo de treinamento do perceptron é análogo ao treinamento de um cão que é estimulado com elogios ou guloseimas quando realiza uma tarefa ou é punido quando não realiza a tarefa. O perceptron é treinado fornecendo dados de entrada e comparando a saída com um resultado esperado. Se a diferença entre a saída do perceptron e a saída esperada é muito grande o perceptron é “punido” e se a diferença for pequena o perceptron é “recompensado”. Essa “punição” ou “recompensa” é feita pelo ajuste dos pesos das conexões (w).
Á medida que o treinamento é repetido o perceptron gradualmente começa a se “ajustar” ao comportamento esperado.
Vamos ver um exemplo simples de treinamento de um perceptron para ser capaz de distinguir fórmulas estruturais de moléculas que contêm um anel de ciclo-hexano das que não contêm um anel, como mostra a Figura Z.3
Figura Z.4. O perceptron deve aprender a distinguir entre moléculas cíclicas e e moléculas abertas (acíclicas) (Fonte: Applications of artificial intelligence in chemistry, 1993)
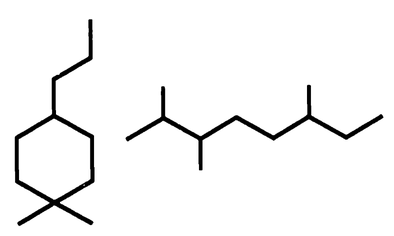
Este é um tipo de problema de grande importância na Inteligência Artificial (IA), o reconhecimento de imagem, no qual as redes neurais artificiais são muito úteis.
O perceptron é inicializado em uma situação de completa "ignorância", sem condições de resolver problemas reais e portanto é necessário uma etapa de treinamento.
O treinamento é feito apresentando ao perceptron exemplos que ele deve “aprender” a interpretar. Esses exemplos constituem o chamado conjunto de treinamento (training set) que é dividido em duas partes:
estímulos de treinamento: conjunto de “entradas” para o perceptron
objetivos do treinamento: conjunto de “saídas” para o perceptron
Para o problema do reconhecimento de anéis em fórmulas estruturais de moléculas o conjunto de entradas (estímulos) consiste em diferentes estruturas moleculares e o conjunto de objetivos é a resposta (saída) esperada para cada entrada, ou seja, “anel-presente” ou “anel-ausente”.
E como fornecer para o percetron os dados representativos de uma fórmula estrutural?
Isso pode ser feito enviando uma matriz com informações dos pixels que formam uma imagem. As regiões com átomos ou ligações são representadas por pixels com maior intensidade luminosa em relação às demais áreas como mostra a Figura Z.5.
Figura Z.5. Diagrama simplificado dos pixels que compõem a imagem de uma fórmula estrutural (Fonte: Applications of artificial intelligence in chemistry, 1993)
O valor de cada pixel multiplicado pelo respectivo peso de conexão é passado para o perceptron, que calcula sua soma e compara com o valor limite. Se somatório for maior do que o limiar de ativação, o perceptron produz uma mensagem “ON” indicando que o perceptron identificou uma molécula cíclica. E se o somatório dos sinais de entrada ficar abaixo do limiar, o perceptron permanecerá “OFF” indicando que se trata de uma molécula sem um anel. (Figura Z.6)
Figura Z.6. Como a informação estrutural pode ser fornecida para o perceptron. (Fonte: Applications of artificial intelligence in chemistry, 1993)
Uma estrutura do conjunto de treinamento é mostrada para o perceptron que “toma uma decisão” e gera uma saída inicial. A saída do perceptron é comparada com o resultado esperado e é calculado um “erro de decisão” que é usado para ajustar os pesos das conexões dos sinais de entrada. Após esse ajuste é apresentada uma outra estrutura e o processo é repetido até que o perceptron atinja o nível satisfatório de acertos na identificação de estruturas.
A saída do perceptron é comparada com o resultado esperado para a molécula na tela e o perceptron é “punido” ou “recompensado” conforme o caso. Se tiver feito a escolha certa, a recompensa é “não alterar” os pesos das conexões. Mas se o perceptron tiver feito a escolha errada é “punido” com a alteração nos pesos das conexões para que seja menos provável cometer o mesmo erro no futuro.
E qual o critério para essa alteração?
Suponha que o perceptron seja ativado com uma molécula acíclica (sem anel), isso significa que a soma dos sinais ponderados ficou maior do que o limiar, e nesse caso os pesos das conexões com os pixels ativos (com luz) são reduzidos. Enquanto que os pesos das conexões com os pixels que não enviaram sinal permanecem inalterados. Não haveria ganho com a alteração dos pesos dos pixels inativos (sem luz) pois não contribuem para o somatório dos sinais de entrada.
Mas se o perceptron permaneceu inativo quando deveria ser ativado significa que o somatório dos sinais que chegam ao perceptron deve ser amplificado e isso é feito aumentando os pesos das conexões com os pixels ativos (com luz). Mas mantendo inalterados os pesos das conexões com pixels inativos (sem luz).
O processo de treinamento pode ser resumido em 3 regras:
Se a saída do perceptron está correta, não faça nada.
Se a saída do perceptron é “ON”, mas deveria ser “OFF”, diminua os pesos das entradas ativas.
Se a saída do perceptron é “OFF”, mas deveria ser “ON” aumente os pesos das entradas ativas.
Após o ajuste dos pesos uma outra estrutura é apresentada, a partir do conjunto de treinamento, e o processo é aplicado a todas as figuras do conjunto de treinamento repetidas vezes.
Na medida em que estruturas são apresentadas sucessivamente ao perceptron o ajuste gradual dos pesos das conexões vão proporcionando um aumento na sua capacidade de discriminar entre os dois tipos de estrutura.
Dessa maneira o perceptron aprende a resolver o problema sem a necessidade de explicitar um roteiro formal para a resolução do problema (algoritmo).
As regras de aprendizagem para o perceptron são simples de implementar mas são “imprecisas”. Eles definem “quais” pesos devem ser ajustados, mas eles não definem o “quanto” ajustar. Uma regra prática é “experimentar” diferentes “taxas de ajuste” que são proporcionais ao “erro de previsão”, o que é conhecida como “taxa de aprendizagem” (learning rate).
Não é possível prever a duração do treinamento para que o perceptron se torne eficaz na identificação de estruturas. Embora os perceptrons possam aprender com rapidez são necessárias muitas passagens através do conjunto de treinamento.
Cada passagem completa através dos exemplos em um conjunto de treinamento é conhecida como uma epoch.
As estruturas que fazem parte do conjunto de treinamento devem ter uma diversidade que seja representativa dos diferentes tipos de moléculas que o perceptron deve aprender a reconhecer. Mas o conjunto de treinamento “não” precisa incluir “todas” as moléculas possíveis.
Nota
A finalidade do treinamento é fornecer exemplos para que o perceptron possa extrair as características mais significativas (features) que permitam distiguir moléculas de diferentes classes. Portanto os exemplos do conjunto de treinamento devem ser representativos, mas não precisam incluir “todas” as possibilidades.
Após a etapa de treinamento os pesos das conexões não são mais alterados e o desempenho do perceptron pode ser avaliado apresentando um conjunto de estruturas desconhecidos e verificando o índice de acertos na previsão do perceptron. Esse conjunto de verificação é também chamado de conjunto de validação (validation set).
Nessa etapa de testes o perceptron é capaz de correlacionar (mapear) um conjunto de entradas (estruturas) a um conjunto de saídas (previsões de classe).
O perceptron é capaz de identificar não apenas as estruturas do conjunto de treinamento mas pode identificar estruturas desconhecidas desde que tenham alguma “relação” com as etruturas do conjunto de treinamento. Ou seja, novas estruturas podem ser identificadas mas “dentro dos limites” das informações contidas no conjunto de treinamento. Ele pode portanto identificar estruturas com anéis de 6 membros (hexano) mas não é capaz de identificar estruturas com 5 membros (pentano) ou 7 membros (heptano).
Em resumo, o perceptron pode “interpolar” mas não “extrapolar”.
Mas apesar dessa limitação o perceptron é capaz de converter uma informação visual em uma informação lógica, uma capacidade com muitas aplicações.
Perceptrons são entidades eficientes mas com capacidade limitada de aprendizagem. Por exemplo, o problema de identificação de estruturas moleculares, descrito na seção anterior, só é possível se as estruturas forem apresentadas sempre com o mesmo tamanho e orientação. Caso contrário um determinado pixel referente a um átomo ou ligação ficará escuro apenas pela mudança da orientação da molécula e dificultando o aprendizado.
Vamos utilizar uma segunda aplicação em Química para ilustrar a limitação dos perceptrons: o monitoramento espectroscópico de amostras em fase gasosa para detectar a presença de poluentes.
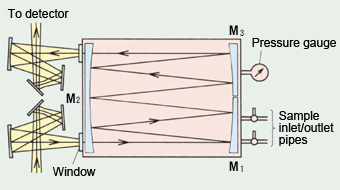
A espectroscopia de absorção no infravermelho, em célula com caminho óptico longo, é uma técnica analítica adequada para a análise de amostras gasosas. Uma amostra gasosa é mantida dentro de uma célula que possui espelhos reflectores nas duas extremidades. Os espelhos refletem o feixe de infravermelho repetidamente, para obter um caminho óptico efetivo maior do que o comprimento físico da célula e assim, aumentar a absorção total do infravermelho. (Figura Z.7).
Figura Z.7. Célula com caminho óptico longo para análise espectroscópica de gases (Fonte: http://www.shimadzu.com)
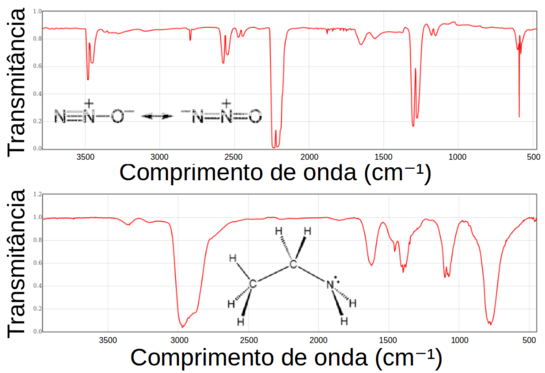
Suponha a análise de amostras gasosas coletadas rotineiramente perto de duas fontes de emissão industrial. Essas amostras são compostas principalmente de ar, mas podem conter eventualmente um dos dois poluentes: óxido nitroso (N2O) ou etilamina (C2H5NH2). (Figura Z.8)
Figura Z.8. Espectros de infravermelho do óxido nitroso e etilamina (Fontes: Espectro N2O NIST e Espectro Etilamina NIST)
Como muitas amostras serão analisadas, o processo foi automatizado com o uso de um perceptron elementar para examinar cada espectro e determinar se um poluente está presente.
O conjunto de treinamento é formado por vários espectros, alguns dos quais mostram a presença de etilamina ou óxido nitroso. Os espectros são digitalizados e passados como sinais de entrada para o perceptron como uma lista de medidas de transmitância em certos comprimentos de onda fixos. (Tabela Z.1 ).
Tabela Z.1. Valores de transmitãncia na região de 600 a 1500 cm-1 dos espectros de infravermelho do óxido nitroso e etilamina. (Fonte: Applications of artificial intelligence in chemistry, 1993)
| Comprimento de onda (cm-1) | Transmitância (%) | |
|---|---|---|
| N2O | C2H5NH2 | |
| 600 | 60 | 76 |
| 700 | 88 | 54 |
| 800 | 89 | 0 |
| 900 | 89 | 52 |
| 1000 | 90 | 77 |
| 1100 | 91 | 18 |
| 1200 | 81 | 80 |
| 1300 | 48 | 72 |
| 1400 | 90 | 16 |
| 1500 | 91 | 50 |
Depois do treinamento o perceptron inicia o monitoramento dos espectros para verificar a presença de um dos dois poluentes (N2O ou C2H5NH2). Em caso afirmativo o perceptron deve gerar um sinal de alerta.
Esta é uma tarefa de classificação de dois estados assim como o problema de identificação de moléculas com anel (poluente presente/ausente). Mas o perceptron funciona de forma confiável até encontrar o espectro mostrado na Figura Z.9.
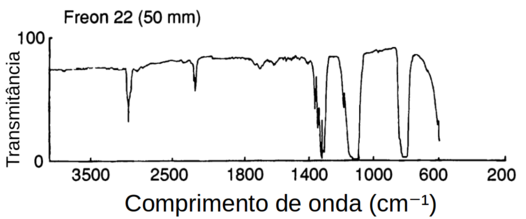
Embora o espectro seja claramente diferente de qualquer um dos poluentes, o perceptron incorretamente dispara o alerta de presença de poluente.
Qual o motivo do erro?
Para entender o motivo do erro, observe que na Tabela Z.1 os poluentes apresentam uma absorbância significativa (ou seja, baixa transmitância) em 1300 cm-1 (N2O) “ou” em 800 cm-1 (C2H5NH2), além de outros comprimentos de onda.
Durante o treinamento, o perceptron associou a alta absorção perto de 800 cm-1 “ou” 1300 cm-1 com a presença de um poluente. No entanto, se os picos aparecem em ambas as posições, isso é uma indicação da ausência de ambos os poluentes, considerando que qualquer amostra contém no máximo uma substância.
O Freon 22 é um hidrocarboneto halogenado que tem potencial de depleção de ozônio (ODP) na atmosfera e portanto, também é um poluente. Mas o perceptron foi treinado para sinalizar a presença apenas dos dois poluentes de interesse ((N2O e C2H5NH2).
Nesse caso o perceptron fêz uma identificação errada porque no espectro do Freon 22 existem absorções em duas regiões simultâneamente (800 cm-1 e a 1300 cm-1).
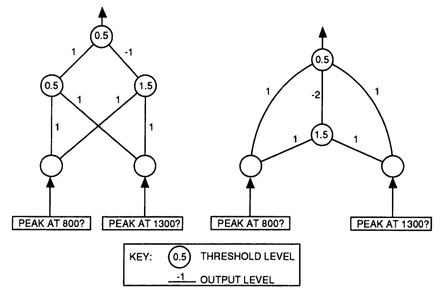
Ou seja, ele não foi capaz de lidar com um problema do tipo XOR (OU Exclusivo), quando a resposta (saída) é verdadeira somente quando “apenas” uma das condições (entradas) é verdadeira. (Tabela Z.2)
Tabela Z.2. Tabela verdade para o teste XOR. (Fonte: Applications of artificial intelligence in chemistry, 1993)
| Problema XOR | Problema Infravermelho | ||||
|---|---|---|---|---|---|
| Entrada x | Entrada y | Saída XOR(x,y) | Abs em 800 cm-1 | Abs em 1300 cm-1 | Poluente presente |
| 0 | 0 | 0 | Não | Não | Não |
| 1 | 0 | 1 | Sim | Não | Sim |
| 0 | 1 | 1 | Não | Sim | Sim |
| 1 | 1 | 0 | Sim | Sim | Não |
As soluções para este problema estão indicadas na Figura Z.10.
Figura Z.10. Possíveis soluções para a identificação dos poluentes a partir do espectro de Infravermelho

A saída do perceptron depende da soma ponderada das entradas (w1s1 + w2s2) e do limiar (Θ) de ativação. Se a soma ponderada das entradas for maior do que o limiar de ativação, o neurônio é ligado e um sinal de saída é gerado.
A soma ponderada das entradas define uma reta sobreposta ao gráfico das “4” possíveis soluções (Figura Z.10).
O perceptron deve identificar a presença de um poluente se um pico aparecer em 800 cm-1 (condição +,-) “ou” 1300 cm-1 (condição -,+), e identificar a ausência de poluente na ausência (condição -,-) “ou” na presença de picos em ambos os comprimentos de onda (condição +,+).
Portanto a linha reta definida pela equação w1s1 + w2s2 deveria separar as 4 possíveis soluções do gráfico da figura Z.10 em dois grupos: absorção apenas em 800 cm-1 (+,- vermelho) e absorção apenas em 1300 cm-1 (-,+ vermelho), e outro grupo: absorções em 800 e 1300 cm-1 (+,+ verde) e sem absorção nessas regiões (-,- verde).
Nota
Mas fica claro que nenhuma linha reta é capaz de fazer essa classificação, e isso é uma evidência de que este problema não pode ser resolvido pelo perceptron, pois “não é um problema linearmente separável”.
Um problema de classificação é “linearmente separável” quando puder ser resolvido por uma reta (espaço 2D) ou um plano (espaço 3D), ou um hiperplano (espaço com N dimensôes).
E como indica a figura Z.10 o problema linearmente separável é o único tipo de problema que o perceptron elementar pode resolver.
Isto representa uma grande limitação pois os problemas científicos mais significativos não são linearmente separáveis, e o pequeno número que são, quase todos são resolvidos de forma mais eficiente por outros métodos.
Em 1969 os pesquisadores Marvin Minsky e Seymour Papert publicaram o artigo “Perceptrons” no qual faziam críticas aos modelos de rede da época, e mostraram em seu estudo teórico que os perceptrons ofereciam possibilidades muito limitadas. Além disso, eles especularam que ampliar a arquitetura de perceptrons para mais camadas não traria nenhuma melhoria significativa nos resultados. Como conseqüência dessa crítica o financiamento das pesquisas para redes neurais foi praticamente encerrado.
As pesquisas só foram retomadas na década de 80 com os trabalhos de Hopfield, Rumelhart, Hinton e Williams, dentre outros, e o desenvolvimento do algoritmo de “retro propagação” (back-propagation) para o treinamento de redes em multicamadas.
O que se descobriu a partir desses trabalhos foi a importância da “interconexão” dessas unidades aritméticas individuais, os neurônios artificiais, formando redes com múltiplas camadas. [34] [35]
Usualmente essas “redes de neurônios” são formadas pela associação de neurônios que formam uma “camada” inicial que recebe os “sinais de entrada” do meio externo, e por isso é chamada de “camada de entrada” (input layer).
Em seguida é introduzida uma nova camada de neurônio chamada de “camada escondida”, que recebe como “sinal de entrada” os “sinais de saída” da camada antecedente (camada de entrada).
E finalmente uma “camada de saída” que se comunica com o “meio externo”, como mostra a figura Z.11 .
Figura Z.11. Uma rede neural simples (Fonte: Applications of artificial intelligence in chemistry, 1993)
A camada de entrada não possui um mecanismo de “ativação” (threshold) e por isso não são “perceptrons” mas servem apenas para distribuir os sinais do meio externo para a camada escondida.
Os neurônios da camada escondida se comunicam com o meio externo somente através do envio e recebimento de sinais para as camadas a que estão diretamente ligados: camada de entrada, saída ou outras camadas escondidas.
Cada neurônio (perceptron) na rede da figura Z.11 está conectado a todos os neurônios das camadas vizinhas mas não existem conexões entre os neurônios de uma mesma camada.
Esse é um exemplo de rede “totalmente conectada com alimentação direta” (fully-connected layered feed forward network), também chamada de perceptron multicamadas, na qual as mensagens (sinais) fluem no sentido da camada de entrada para a camada de saída.
Nota
Se houver conexões entre os neurônios de uma mesma camada, as redes são denominadas recorrentes. (Fonte: Um mergulho profundo nas redes neurais recorrentes)
Os exemplos anteriores de identificação de moléculas com anel e o monitoramento espectroscópico para a detecção de poluentes ilustram que a “aprendizagem” é, em parte, um processo de “classificação”.
Nos exemplos citados é feita uma “classificação em dois estados” onde se reconhece algo e se faz uma atribuição a uma ou outra classe com base em informações de definição que são os critérios de classificação.
Na classificação (ou agrupamento) de um elemento de um grupo, apesar de ter algumas características semelhantes com os demais, é separado pois pertence a uma classe (ou grupo) diferente.
Na identificação de moléculas com anel o perceptron pode classificar um conjunto de itens em duas classes desde que os itens sejam linearmente separáveis como mostra a figura Z.12.
Figura Z.12. Problema linearmente separável (Fonte: Applications of artificial intelligence in chemistry, 1993)
Mas as redes em camadas podem ser usadas em aplicações cujas soluções NÃO são linearmente separáveis.
Vamos considerar como uma rede neural poderia ser usada para monitorar a temperatura e o pH em uma reação.
Considere uma reação na qual a temperatura não pode passar de 95°C e o pH não pode ficar abaixo de 4,5. Se qualquer um dos parâmetros sair dos limites estabelecidos a rede deve gerar um alarme. (Figura Z.13)
Figura Z.13. Gráfico das condições de controle de uma reação. Na região verde a reação está sob controle e nas regiões vermelhas está fora de controle e a rede neural deve gerar um alarme.

Um exemplo de combinação de dois problemas linearmente separáveis gerando um problema linearmente inseparável, para o qual um perceptron não é capaz de fazer o monitoramento. Mas uma pequena rede, como na figura Z.14 é capaz de monitorar.
Figura Z.14. Diagrama de uma pequena rede neural monitorando as condições de pH e temperatura de uma reação.
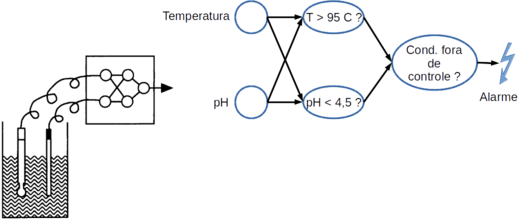
As entradas para a camada escondida desta rede são fornecidas pelos sensores analógicos de pH e temperatura do interior da reação. Um dos perceptrons da camada escondida monitora a temperatura e é ativado se a temperatura ultrapassar 96 °C, mas ignora completamente o sinal de pH. O segundo perceptron da camada escondida monitora o pH e é ativado se o pH ficar abaixo de 4,5, mas ignora o valor da temperatura.
A saída dos dois perceptrons da camada escondida é combinada em um único perceptron na camada de saída, o qual gera um sinal de alarme se um dos perceptrons da camada escondida enviar um sinal “on”.
Essa rede simples classifica as condições do reator de acordo com duas variáveis independentes e portanto pode ser usada em situações nas quais as soluções são “linearmente inseparáveis”. Outras variáveis de controle podem ser adicionadas na rede (Ex: viscosidade, turbidez etc) tornando ainda mais restritiva a região de controle indicada na figura Z.13.
Redes semelhantes podem ser usadas para resolver o problema da identificação dos poluentes a partir do espectro de Infravermelho como mostra a figura Z.15.
Figura Z.15. Duas possíveis redes neurais para a solução do problema de classificação de poluentes por infravermelho. (Fonte: Applications of artificial intelligence in chemistry, 1993)
No entanto essas redes ainda apresentam um limitação para serem usadas em problemas de classificação mais complexos, pois não são capazes de “aprender”, ou seja, não são capazes de ajustar os pesos das conexões e os limiares de ativação de maneira “autônoma”.
O processo de “aprendizagem” se tornou possível com a implantação de duas importantes modificações:
funções de “limiar de ativação” modificadas
algoritmos de retropropagação
Para permitir o processo de aprendizado dos perceptrons é necessário uma função de ativação que permita gerar um sinal de saída “proporcional” ao somatório dos sinais de entrada. E dessa forma permitindo uma “transferência de informação” entre as camadas da rede.
Essa modificação na função de ativação visa aproximar o comportamento dos percetrons do comportamento dos neurônios reais. Afinal os neurônios reais não são entidades “binárias” assumindo apenas dois estados (ON ou OFF), mas geram um sinal de saída que é “proporcional” aos sinais de entrada.
Dois tipos de função de ativação podem ser usadas em redes “totalmente conectada com alimentação direta” (fully-connected layered feed forward network): função linear e função sigmóide.
Com a aplicação de uma função de ativação linear o sinal de saída do perceptron é 0 (OFF) se o somatório dos sinais de entrada for menor que o limiar Θl, e totalmente ON se o somatório dos sinais de entrada for maior do que o limiar Θu. E entre os limites Θl e Θu o sinal de saída é uma função linear do somatório dos sinais de entrada como mostra a figura Z.16.
Figura Z.16. Função de ativação linear (Fonte: Applications of artificial intelligence in chemistry, 1993)
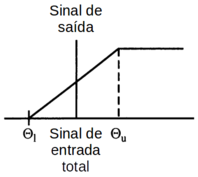
Essa função de ativação permite que alguma informação sobre a intensidade dos sinal seja passada de uma camada para as seguintes.
Mas a função de ativação (ou de transferência) mais usada é a função sigmóide que apresenta uma variação nos extremos nos quais o perceptron está totalmente ON ou totalmente OFF como mostra a figura Z.17
Figura Z.17. Função de ativação (ou de transferência) sigmoide (Fonte: Applications of artificial intelligence in chemistry, 1993)
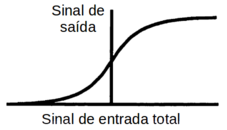
A função sigmóide é definida pela equação Z.1.
A função sigmóide “tende” a 0 para x = -∞ e tende a 1 para x = +∞
Uma outra vantagem do uso da função sigmóide como função de ativação é oferecer um “controle de ganho automático” permitindo que sinais de baixa intensidade e sinais de alta intensidade possam ser simultâneamente recebidos pela rede sem que o sinal de baixa intensidade seja “suprimido” pelo sinal de alta intensidade com a consequente perda de informação.
Isso é possível pois a atenuação do sinal é pequena para sinais de baixa intensidade e cresce exponencialmente para sinais de alta intensidade.
A incorporação da função sigmóide aproxima um pouco mais a analogia entre uma rede neural artificial e uma rede natural. Mas ainda persiste a questão de como fazer o ajuste dos pesos das diferentes conexões da rede.
No perceptron elementar as regras de aprendizagem (ajuste dos pesos) é simples e direta mas ela não se aplica para o ajuste das conexões entre as diferentes camadas de uma rede.
Dentre os vários algoritmos que foram propostos para o problema do aprendizado o mais popular é o algoritmo de “retropropagação” (backpropagation).
Vamos usar como exemplo uma rede genérica com 1 camada escondida (Figura Z.18) para ilustrar as etapas do algoritmo de retropropagação.
Figura Z.18. Uma rede neural genérica com “I” neurônios na camada de entrada, “J” neurônios na camada escondida e “K” neurônios na camada de saída. (Fonte: Mutli-Layer Perceptron - Back Propagation)
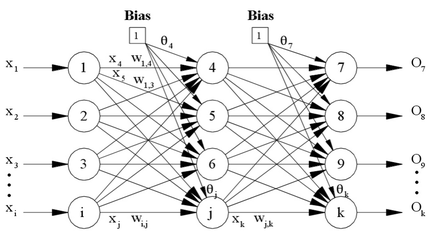
A primeira etapa de treinamento é a inserção de um conjunto de dados de treinamento nos neurônios de entrada e a “propagação” do sinal através das camadas escondidas até a camada de saída.
A primeira etapa da retropropagação é o cálculo do erro do sinal na camada de saída que deve ser “retropropagado”, de maneira “proporcional” para as camadas internas, cujo objetivo final é “reduzir o erro do sinal de saída”.
Em seguida é usada uma equação para calcular o ajuste dos pesos na camada de saída, e outra equação para o cálculo do ajuste dos pesos das conexões entre os neurônios das camadas escondidas.
O cálculo do ajuste nos pesos das conexões é feito com o uso do algoritmo do gradiente descendente que visa minimizar o erro global (Figura Z.2).
Equação Z.2. Cálculo do erro global da rede (Função Erro - E)
E = ½ ∑P ( ∑K ( TPK − OPK )2 )
TPK : sinal esperado para o neurônio de saída K com os parâmetros de treinamento P
OPK : sinal de saída real do neurônio K com os parâmetros de treinamento P
Após o ajuste é inserido outro conjunto de dados de treinamento nos neurônios de entrada e repetida as operações de “propagação” do sinal e “retropropagação” do erro para ajuste dos pesos.
Essa sequência é repetida várias vezes até que o erro global do sinal de saída seja reduzido a um “mínimo aceitável”.
Inicialmente calculamos a diferença entre o sinal esperado para o neurônio de saída k (Tk) e a saída real do neurônio k (Ok), equação Z.3:
Equação Z.3. Cálculo do erro do neurônio de saída (Δk)
Tk : sinal esperado para o neurônio de saída k
Ok : sinal de saída real do neurônio k
Δk = Tk − Ok
A diferença Δk é multiplicada pela derivada da função de ativação (sigmóide) segundo a equação Z.4:
Equação Z.4. Derivada da função sigmóide
Função sigmóide: g(x) = (1 + e−x) −1
Derivada da função sigmóide: g'(x) = g(x) × (1 − g(x))
Ok: sinal de saída real do neurônio k
Ok × (1 − Ok)
Para cada neurônio de saída calculamos o parâmetro “delta” (δk) que corresponde ao produto de Δk pela derivada da função de ativação conforme a equação Z.5:
Equação Z.5. Cálculo do delta do neurônio de saída (δk)
δk = Δk × Ok ×(1 − Ok)
δk = (Tk − Ok) × Ok ×(1 − Ok)
Em seguida o parâmetro “delta” (δk) é usado para corrigir os pesos das conexões (W) entre os neurônios da última camada escondida (J) e os neurônios da camada de saída (K).
A variação no peso de cada conexão é proporcional ao erro do neurônio de saída (δk) multiplicado pelo sinal de ativação do neurônio da última camada escondida (Oj) Z.6:
Equação Z.6. Cálculo do ajuste no peso da conexão do neurônio da camada de saída (K) com o neurônio da última camada escondida (J) (ΔWjk)
ΔWjk = Lr × δk × Oj
Onde:
ΔWjk = ajuste do peso da conexão entre o neurônio da camada escondida J com o neurônio da camada de saída K
Lr = taxa de aprendizagem (Ex: 0,1)
δk = erro do sinal do neurônio da camada de saída K
Oj = sinal de entrada do neurônio da camada de saída que corresponde ao sinal de ativação do neurônio da última camada escondida J
E portanto o peso da conexão no próximo estágio de treinamento (t+1) é dado pela equação Z.7:
Equação Z.7. Cálculo do peso da conexão do neurônio da última camada escondida no estágio (t+1) a partir do peso no estágio (t) e do ajuste (ΔWjk)
Wjk (t+1) = Wjk (t) + Lr × δk × Oj
A sequência de ajuste dos pesos para um neurônio na camada de saída pode ser esquematizada pelo diagrama da figura Z.19.
Figura Z.19. Diagrama da sequência de cálculo do ajuste dos pesos das conexões de um neurônio na camada de saída. (Imagem Ampliada)
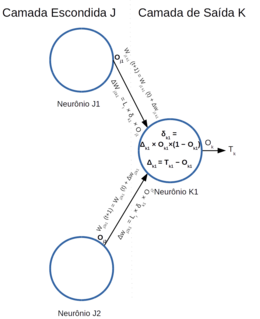
A próxima etapa é a “retropropagação” do erro para os neurônios das camadas escondidas. Mas nesse caso o gradiente do erro (δ) para os neurônios da(s) camada(s) escondida(s) é o produto da derivada da função de ativação do neurônio pelo somatório do produto dos erros pelos pesos das conexões com os neurônios da camada posterior.
Uau! Que confusão!
Vamos explicar melhor.
Por exemplo, o parâmetro de erro “delta” (δj1) para o neurônio 1 da camada J (ver Figura Z.19) é calculado pela equação Z.8:
Equação Z.8. Cálculo do parâmetro de erro “delta” de um neurônio na camada escondida J conectado a um neurônio na camada de saída K
δj = Oj × (1 − Oj) ∑k ( δk × Wjk )
O diagrama da figura Z.20 ilustra o cálculo do parâmetro de erro “delta” de um neurônio na camada escondida J.
Figura Z.20. Diagrama da sequência de cálculo do parâmetro de erro “delta” do neurônio 1 na camada escondida J (δj1).(Imagem Ampliada)

E a partir de (δj1) é possível calcular o ajuste nos pesos das conexões do neurônio na camada J com os neurônios na camada escondida antecedente (ou camada de entrada se houver apenas uma camada escondida) usando a equação Z.9.
Equação Z.9. Cálculo do ajuste do peso da conexão de um neurônio da camada escondida J com um neurônio na camada anterior I, que pode ser outra camada escondida ou de entrada
ΔWij = Lr × δj × Oi
Wij(t + 1) = Wij(t) + ΔWij
Todas as etapas do algoritmo de retropropagação estão indicadas no diagrama da figura Z.21
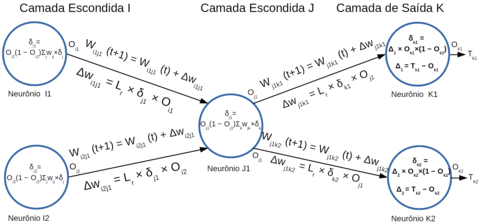
A técnica utilizada pelo algoritmo de retropropagação é conhecida como regra delta ou gradiente descendente parte do princípio de que o ajuste dos pesos das conexões nas camadas escondidas depente do erro nas camadas subsequentes. Por isso o ajuste é feito primeiro na camada de saída onde o cálculo de erro é simples e direto pois se conhece o valor real (O - Output) e o valor esperado (T - Target).
A partir daí o erro é propagado sucessivamente para as camadas interiores, onde cada conexão recebe um ajuste proporcional à sua contribuição para o erro no sinal de saída. Ou seja, quanto maior a contribuição para o erro maior o ajuste.
Podemos resumir o algoritmo de retropropagação com o seguinte pseudocódigo: (Fonte: Mutli-Layer Perceptron - Back Propagation)
################################################################
#analisar a estrutura dos dados para definir o número de neurônios na camada de entrada e de saída.
#definir o número de camadas escondidas e quantos neurônios em cada camada.
#selecionar os dados de treinamento e de validação.
#inicializar todos os pesos com números aleatórios, geralmente entre -1 e 1, e o bias (threshold)
repetir
para cada grupo de dados de entrada do conjunto de treinamento
atribuir os dados aos neurônios de entrada
#Propagar os sinais de entrada ao longo da rede
para cada camada da rede
para cada neurônio na camada
1. Calcular a soma ponderada dos sinais no neurônio
2. Adicionar o bias
3. Calcular a sinal de ativação para o neurônio
fim
fim
#Retropropagar os erros através da rede
para cada neurônio na camada de saída
calcular o sinal de erro delta (δ)
fim
para todas as camadas escondidas
para cada neurônio na camada
1. Calcular o sinal de erro
2. Atualizar o peso de cada conexão em cada neurônio da rede
fim
fim
#Calcular o Erro Global
Calcular a função de erro
fim
enquanto ((número_máximo_interações < limite_interações) & (função_de_erro > limite_erro))
################################################################
No entanto o algoritmo de retropropagação, ao tentar minimizar o erro, pode levar a um ponto de “mínimo local” ao invés do “mínimo global”como mostra a figura Z.22.
Figura Z.22. A partir de um nível de erro “A” o algoritmo de retropropagação pode chegar a um ponto “mínimo local” (C) ou um ponto “mínimo global” (B).(Fonte: Chapter 2 The Backprop Algorithm)
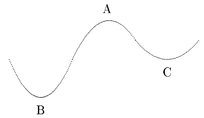
Uma rede que tenha sido treinada até um mínimo local pode ainda ser usada para fazer interpolações e extrapolações (generalizações) mas não com a mesma exatidão de uma rede treinada até um mínimo global.
Outra questão a ser considerada quanto ao treinamento de uma rede neural é o “quanto uma rede se ajusta ao conjunto de dados” tanto para extrapolação quanto para interpolação.
Dependendo do número de neurônios e do número de etapas de treinamento uma rede pode ficar “sobre-ajustada” (over-fitting) ou “sub-ajustada” (under-fitting).
Uma rede “sub-ajustada” (under-fitting) não é capaz de representar adequadamente o conjunto de dados como ilustra a figura Z.23.
Figura Z.23. Uma rede “sub-ajustada” (under-fitting) não é capaz de detectar o padrão representado pelos dados e portanto não pode fazer previsões com uma exatidão satisfatória. (Fonte: Mutli-Layer Perceptron - Back Propagation)
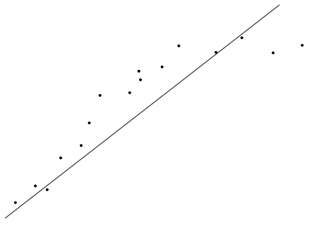
Esse problema pode acontecer em uma rede com poucos neurônios na camada escondida e portanto sem a “complexidade” compatível com a “complexidade” do conjunto de dados. Mas também pode ser devido a um treinamento “insuficiente”, com poucas etapas.
No outro extremo temos o problema do “sobre-ajuste” (over-fitting) no qual a rede “reproduz com exatidão” o comportamento da série de dados e portanto faz interpolações com exatidão mas perde a capacidade de fazer extrapolações, ou seja, de “generalizar” e fazer previsões fora da faixa representada pelos dados de treinamento. (Figura Z.24).
Figura Z.24. Uma rede “sobre-ajustada” (over-fitting) se ajusta “rigorosamente” ao padrão dos dados de treinamento incorporando até mesmo a incerteza dos dados, mas é incapaz de fazer generalizações (extrapolar). (Fonte: Mutli-Layer Perceptron - Back Propagation)
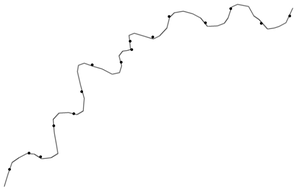
O sobre-ajuste costuma acontecer quando se tem uma grande quantidade de neurônios na camada escondida ou devido a um treinamento “excessivo” da rede. Nesse caso a rede “incorpora” na sua estrutura a “incerteza” (o ruído) presente nos dados.
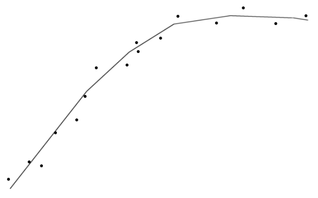
O ideal é uma rede com o número “mínimo necessário” de neurônios e que após o treinamento seja capaz de se ajustar “bem” ao conjunto de dados e fazer interpolações e extrapolações com “baixa” incerteza. (Figura Z.25)
Figura Z.25. Uma rede “bem-ajustada” (right-fitting) se ajusta ao padrão dos dados de treinamento sem incorporar o “ruído” (incerteza) associado aos dados. (Fonte: Mutli-Layer Perceptron - Back Propagation)