Considerando a grande utilidade das Redes Neurais Artificiais em várias aplicações, mas principalmente as possíveis aplicações em Química (Neural Networks in Chemistry, Applications of Artificial Neural Networks in Chemical Problems e Redes Neurais e suas Aplicações em Calibração Multivariada) resolvi implementar do zero (from scratch) um programa baseado na técnica de Redes Neurais usando a linguagem Tcl/Tk.
O programa foi desenvolvido seguindo o paradigma da programação estruturada conforme a sequência:
Definir o número de neurônios da camada de entrada
Definir o número de camadas escondidas com os respectivos neurônios
Definir o número de neurônios na camada de saída
Definir os pesos das conexões
Definir o bias
Abrir o arquivo de dados para treinamento (dataset)
Ler os dados de entrada
Escrever os dados de entrada nos neurônios da camada de entrada
Propagar o sinal ao longo da rede
Exibir a(s) saída(s)
Calcular o erro
Retropropagar o erro
Repetir a partir da etapa 7 até o final do dataset
A Rede Neural foi estruturada em uma variável do tipo dicionário com uma estrutura representada na figura Z.26.
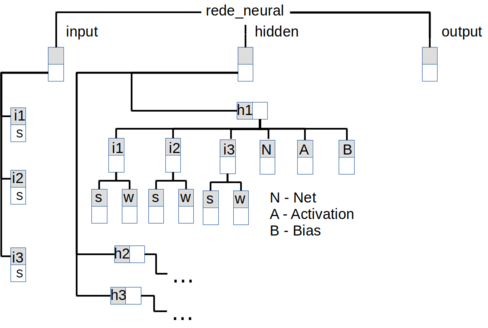
A variável armazena em diferentes níveis os neurônios de cada camada, os sinais, os pesos das conexões, o somatório do sinal de entrada (Net), o bias e o sinal de ativação (Activation).
O procedimento buildInputLayer cria os neurônios da camada de entrada e recebe como argumentos a variável do tipo dict neural_network, que armazena a estrutura da rede, e a variável do tipo list input_l que define os número de neurônios da camada de entrada:
#Procedimento para a criação dos neurônios da camada de entrada (input)
#A chave (key) “activation” armazena a saída (output) de cada neurônio
proc buildInputLayer { neural_network input_l } {
upvar 1 $neural_network n_n
upvar 1 $input_l i_l
foreach neuron $i_l {
dict set n_n input $neuron activation output_$neuron
}
}
O procedimento buildHiddenLayers cria a estrutura das camadas escondidas e recebe como argumentos as variáveis do tipo dict neural_network e hidden_l que define o número de neurônios na camada escondida:
proc buildHiddenLayers { neural_network hidden_l} {
upvar 1 $neural_network n_n
upvar 1 $hidden_l h_l
foreach layer [dict keys $h_l] {
#Create the neurons of first hidden layer
foreach neuron [dict get $h_l $layer] {
foreach id_input [dict keys [dict get $n_n input ] ] {
#Obtendo a entrada de cada neurônio da camada input
set s [dict get $n_n input $id_input activation]
dict set n_n $layer $neuron $id_input signal $s
dict set n_n $layer $neuron $id_input weight w
}
#Criação dos campos para armazenar o somatório das entradas (net) e a saída (output)
dict set n_n $layer $neuron net sum_input_$neuron
dict set n_n $layer $neuron activation output_$neuron
#Se houver necessidade podemos incluir o "bias"
dict set n_n $layer $neuron bias b
#Parâmetro delta para o cálculo do erro
dict set n_n $layer $neuron delta delta_$neuron
}
break
}
#Create the neurons of the remainder hidden layers
foreach layer [lrange [dict keys $h_l] 1 end] {
#The returned keys will be in the order that they were inserted into the dictionary!
set last_hidden_layer [lindex [dict keys $n_n] end]
foreach neuron [dict get $h_l $layer] {
foreach id_hidden [dict keys [dict get $n_n $last_hidden_layer ] ] {
#Getting the output of each neuron from the last hidden layer
set s [dict get $n_n $last_hidden_layer $id_hidden activation]
dict set n_n $layer $neuron $id_hidden signal $s
dict set n_n $layer $neuron $id_hidden weight w
}
#Criação dos campos para armazenar o somatório das entradas (net) e a saída (output)
dict set n_n $layer $neuron net sum_input_$neuron
dict set n_n $layer $neuron activation output_$neuron
#Se houver necessidade podemos incluir o "bias"
dict set n_n $layer $neuron bias b
#Parâmetro delta para o cálculo do erro
dict set n_n $layer $neuron delta delta_$neuron
}
}
}
E o procedimento buildOutputLayer cria os neurônios de saída:
proc buildOutputLayer { neural_network output_l } {
upvar 1 $neural_network n_n
upvar 1 $output_l o_l
#Last hidden layer to be used no create the connections to the output layer
set last_hidden_layer [lindex [dict keys $n_n] end]
#Criando os neurônios da camada de saída
#A camada de saída só vai precisar da saída de cada neurônio da camada escondida (hidden)
foreach neuron $o_l {
set n_l_h_l [dict keys [dict get $n_n $last_hidden_layer]]
foreach id_hidden [dict keys [dict get $n_n $last_hidden_layer]] {
set s [dict get $n_n $last_hidden_layer $id_hidden activation]
dict set n_n output $neuron $id_hidden signal $s
dict set n_n output $neuron $id_hidden weight w
}
#Criação dos campos para armazenar o somatório das entradas (net), a saída (output) e o bias
dict set n_n output $neuron net sum_input_$neuron
dict set n_n output $neuron activation output_$neuron
dict set n_n output $neuron bias b
#Parâmetro delta para o cálculo do erro
dict set n_n output $neuron delta delta_$neuron
}
}
O número de camadas e o número de neurônios em cada camada é definido pelas variáveis: input_neurons, hidden_layers e output_neurons.
#Definindo o número de camadas e o número de neurônios em cada camada
#Definição dos neurônios da camada de entrada (input)
#in - id da entrada
set input_neurons {i1 i2}
#Criação das camadas escondidas (hidden) com os respectivos neurônios
dict set hidden_layers hidden_1 {1h1 1h2 1h3}
dict set hidden_layers hidden_2 {2h1 2h2 2h3}
dict set hidden_layers hidden_3 {3h1 3h2 3h3}
dict set hidden_layers hidden_4 {4h1 4h2 4h3}
#Lista dos neurônios na camada de saída
set output_neurons {o1}
A estrutura da rede neural é armazenada na variável rede_neural do tipo “dict” (dicionário) e é inicializada com os seguintes comandos:
#Criação de uma rede neural usando uma variável do tipo "dicionário" (rede_neural) #Criando a camada de entrada buildInputLayer rede_neural input_neurons #Criando a(s) camada(s) escondida(s) buildHiddenLayers rede_neural hidden_layers #Criando a camada de saída buildOutputLayer rede_neural output_neurons
O número de neurônios na camada de saída deve ser igual ao número de possíveis “saídas” do problema (ou número de classes). Por exemplo, se for uma classificação binária (2 classes) a rede deverá ter dois neurônios na camada de saída.
Com a estrutura da rede já definida é hora de gerar os pesos das conexões com valores aleatórios entre 0 e 1 com o procedimento initWeight.
proc initWeight { neural_network } {
upvar 1 $neural_network nn
#Remove the first layer (input)
set all_layers [dict keys $nn]
set layers [ lrange $all_layers 1 end ]
foreach l $layers {
set neurons [dict keys [dict get $nn $l]]
foreach n $neurons {
set keys [dict keys [dict get $nn $l $n]]
foreach k $keys {
if [dict exists $nn $l $n $k weight] {
dict set nn $l $n $k weight [expr rand()]
puts "Pesos iniciais para $n $k: [dict get $nn $l $n $k weight]"
}
}
}
}
}
E em seguida inicializar o bias com o procedimento initBias.
#Procedimento para inicializar os bias
proc initBias { neural_network b } {
upvar 1 $neural_network nn
#Remove the first layer (input)
set all_layers [dict keys $nn]
set layers [ lrange $all_layers 1 end ]
foreach l $layers {
set neurons [dict keys [dict get $nn $l]]
foreach n $neurons {
set keys [dict keys [dict get $nn $l $n]]
foreach k $keys {
if {$k == "bias"} { dict set nn $l $n bias $b }
}
}
}
}
Esses procedimentos são executados com os comandos:
#Inicializando o weight com valores aleatórios entre 0 e 1 initWeight rede_neural #Inicializando o bias initBias rede_neural 0
Após a criação, na memória, da estrutura da rede neural ela poderia ser treinada imediatamente. Mas, em algum momento teria que ser armazenada em um arquivo em disco para ser usada posteriormente.
Resolvi implementar as operações de gravação e leitura da estrutura da rede neural com os procedimentos saveNeuralNetwork e openNeuralNetwork respectivamente.
#Procedure to save the neural network in a file
#Wojciech Kocjan e Piotr Beltowski, Tcl 8.5 Network Programming, page 205
proc saveNeuralNetwork { neural_network file_name } {
upvar 1 $neural_network n_n
set channel [open $file_name w]
puts $channel $n_n
close $channel
}
#Procedure to open the file with the neural network structure
#Wojciech Kocjan e Piotr Beltowski, Tcl 8.5 Network Programming, page 205
proc openNeuralNetwork { file_name } {
set channel [open $file_name r]
set neural_network [read $channel]
close $channel
return $neural_network
}
E, na sequência, executar as operações de gravação e leitura com os comandos:
#Save the neural network structure in file saveNeuralNetwork rede_neural rede_neural.txt #Unset the variable just to check commands save and open #unset rede_neural #Read the neural network from file set rede_neural [openNeuralNetwork rede_neural.txt]
Para abrir o arquivo com os dados de treinamento (Dataset) implementamos o procedimento openDatasetFile.
#Open the file with the dataset and receive as parameter the name of the file
#openDatasetFile
proc openDatasetFile { file_name } {
set channel [open $file_name r]
set dataset [read $channel]
close $channel
return $dataset
}
Ler o arquivo de dados e armazenar o identificador na variável dataset.
#Read the dataset from file set dataset [openDatasetFile dataset_00.txt]
Definimos:
input: entradas da rede neural
output: saídas da rede neural
target: resultados esperados
Após abrir o arquivo com o dataset é preciso definir os campos correspondentes à entrada e os campos correspondentes à saída. E para isso implementamos o procedimento readInputs que irá ler os campos de entrada em cada registro e retornar uma lista de listas contendo os dados de entrada.
#Read the input fields from dataset and extract the label if necessary
#The fields are separated by space
#the parameter input_fields is a list with the numbers of fields which contain the inputs
proc readInputs { dataset input_fields label} {
set dataset_list [split $dataset "\n"]
#Remove the first record if it is a label
if {$label} { set dataset_list [lreplace $dataset_list 0 0] }
set input_list {}
foreach record $dataset_list {
if { $record != "" } {
set inputs {}
foreach field $input_fields {
lappend inputs [lindex $record [expr $field - 1]]
}
lappend input_list $inputs
}
}
return $input_list
}
Os campos referentes aos dados de entrada são armazenados na variável input_list com o comando:
#Split the dataset in list of inputs with the parameters { dataset input_fields label (boolean) }
#input_fields is the number of fields of inputs
set input_list [readInputs $dataset {1 2} 1]
#puts "input_list: $input_list"
O comando readInputs recebe como argumentos o identificador do arquivo de dados (dataset), uma lista indicando os campos referentes aos dados de entrada (input_fields) e um argumento (label) do tipo boolean (0 ou 1) para indicar se a primeira linha do arquivo é um comentário que deve ou não ser descartado.
No exemplo anterior os campos 1 e 2 são campos de dados e o argumento label com valor “1” indica que a primeira linha do arquivo contém informações sobre o arquivo que deve ser descartada.
E para ler os campos contendo os dados de saída (target) implementamos o procedimento readTarget:
#Read the target(s) from the dataset
proc readTargets { dataset target_fields label } {
set dataset_list [split $dataset "\n"]
#Remove the first record if it is a label
if {$label} { set dataset_list [lreplace $dataset_list 0 0] }
set target_list {}
foreach record $dataset_list {
if { $record != "" } {
set targets {}
foreach field $target_fields {
lappend targets [lindex $record [expr $field - 1]]
}
lappend target_list $targets
}
}
return $target_list
}
Da mesma forma que readInputs o procedimento readTargets recebe como argumento os números dos campos com as saídas e um indicador se a primeira linha do dataset deve ser desconsiderada.
#Split the dataset in list of targets with the parameters { dataset target_fields label (boolean) }
#if the targets are stored in more than one field the parameter target_fields could be passed as a list
set target_list [readTargets $dataset { 3 } 1]
É importante lembrar que o número de campos de dados de entrada deve ser igual ao número de neurônios na camada de entrada (input layer). E o número de elementos na lista de resultados esperados deve ser igual ao número de neurônios na camada de saída (output layer) para que o procedimento calcErrorOutputLayer possa atribuir a cada neurônio da camada de saída um dos elementos do parâmetro “target_list”.
O procedimento calcErrorOutputLayer foi implementado para calcular o erro de predição, ou seja, a diferença entre os valores gerados pela rede e os valores esperados conforme o Dataset, e o valor de delta.
#Calculate the error
#The parameters target_list (and the dataset) must be formatted in such a way that each item of list target_list
#corresponds to the target of each output neuron
proc calcErrorOutputLayer { neural_network target_list } {
upvar 1 $neural_network n_n
set output_neurons_list [dict keys [dict get $n_n output]]
if { [llength $output_neurons_list] != [llength $target_list] } {
puts "ERROR - number of targets is different from number of output neurons"
return 0
}
foreach o_n $output_neurons_list t $target_list {
set output_signal [dict get $n_n output $o_n activation]
set error [expr $t - $output_signal]
sumErrorPrediction $error
# puts "calcErrorOutputLayer error: $error"
set delta [expr [expr $t - $output_signal] * [expr $output_signal * (1 - $output_signal)]]
dict set n_n output $o_n delta $delta
}
return 1
}
Para exibir no terminal a estrutura da rede neural implementamos o procedimento printNeuralNetwork:
proc printNeuralNetwork { neural_network } {
upvar 1 $neural_network rede_neural
puts "Rede Neural"
foreach layer [dict keys $rede_neural] {
puts "Camada $layer"
puts [dict get $rede_neural $layer]
foreach neuron [dict keys [dict get $rede_neural $layer]] {
puts "Neurônio $neuron da camada $layer"
puts [dict get $rede_neural $layer $neuron]
foreach key [dict keys [dict get $rede_neural $layer $neuron]] {
if [dict exists $rede_neural $layer $neuron $key weight] {
set w [dict get $rede_neural $layer $neuron $key weight]
puts "O peso (weight) da conexão do neurônio $neuron com o neurônio $key é $w"
}
}
}
}
}
proc printNeuralNetwork { neural_network } {
upvar 1 $neural_network rede_neural
puts "Rede Neural"
foreach layer [dict keys $rede_neural] {
puts "Camada $layer"
puts [dict get $rede_neural $layer]
foreach neuron [dict keys [dict get $rede_neural $layer]] {
puts "Neurônio $neuron da camada $layer"
puts [dict get $rede_neural $layer $neuron]
foreach key [dict keys [dict get $rede_neural $layer $neuron]] {
if [dict exists $rede_neural $layer $neuron $key weight] {
set w [dict get $rede_neural $layer $neuron $key weight]
puts "O peso (weight) da conexão do neurônio $neuron com o neurônio $key é $w"
}
}
}
}
}
E é executado com o comando:
printNeuralNetwork rede_neural
Com a rede estruturada e o dataset carregado é hora de iniciar o treinamento da rede com o seguinte loop:
set i 0
while { $i < 1000 } {
foreach input_record $input_list target_record $target_list {
puts "\n\nProcessing input_record: $input_record target_record: $target_record"
#set the inputs to the input neurons
if { ![writeInputs rede_neural $input_record] } { break }
#propagate the signal through the network
propagateInputs rede_neural
#print the signal of output neurons
printOutputs rede_neural
if { ![calcErrorOutputLayer rede_neural $target_record] } { break }
backPropagateError rede_neural
#Exibindo a rede
# printNeuralNetwork rede_neural
}
incr i
}
O loop de treinamento lê os dados de entrada (input_record) e de saída (target_record):
foreach input_record $input_list target_record $target_list {
Escreve os dados de entrada nos neurônios de entrada e verifica se o número de campos de entrada corresponde ao número de neurônios de entrada:
#set the inputs to the input neurons
if { ![writeInputs rede_neural $input_record] } { break }
Propaga o sinal através das camadas da rede:
#propagate the signal through the network propagateInputs rede_neural
Calcula o erro para cada neurônio de saída:
if { ![calcErrorOutputLayer rede_neural $target_record] } { break }
E faz a retropropagação do erro:
backPropagateError rede_neural
Essas etapas são repetidas quantas vezes forem necessárias para minimizar o erro de predição conforme o valor de i e a rede neural, com os pesos das conexões otimizados, é gravada em um arquivo com o comando:
#Save the neural network in file saveNeuralNetwork rede_neural rede_neural.txt
Agora vamos incluir mais algumas funcionalidades para “acompanhar” a variação do erro de predição e exibir em gráfico a variação do erro ao longo dos ciclos de treinamento.
Para isso criamos a variável list_error_prediction e mais 3 procedimentos: resetSumErrorPrediction, sumErrorPrediction e getSumErrorPrediction.
#Procedures to control error predicition
proc resetSumErrorPrediction {} {
global sum_error_prediction
set sum_error_prediction 0.0
}
proc sumErrorPrediction { e } {
global sum_error_prediction
set e [expr pow($e,2)]
set sum_error_prediction [expr $sum_error_prediction + $e]
}
proc getSumErrorPrediction {} {
global sum_error_prediction
return $sum_error_prediction
}
E para exibir em gráfico a variação do erro ao longo do treinamento usamos a biblioteca Plotchart:
#######################################################################################
#Graph
#Cria o widget canvas onde será construído o gráfico
canvas .c -background white -width 1000 -height 600
pack .c -fill both
#Get the max error
#set formated_list_error_prediction [regsub -all " " $list_error_prediction ","]
#puts "Valor máximo do erro: [ expr max($formated_list_error_prediction)]"
#or
set max_error [lindex [lsort -real $list_error_prediction] end]
#set max_error [format "%.1f" $max_error]
set num_epoch [llength $list_error_prediction]
set interval_error [expr round($max_error / 10)]
#set interval_error [format "%.4f" $interval_error]
set interval_epoch [expr $num_epoch / 10]
puts "max_error: $max_error num_epoch: $num_epoch interval_error: $interval_error interval_epoch: $interval_epoch"
# Cria o gráfico com os eixos x e y
set lim_epoch [list 0 $num_epoch $interval_epoch]
set lim_error [list 0 $max_error $interval_error]
set s [::Plotchart::createXYPlot .c $lim_epoch $lim_error]
# Loop foreach que executa o comando "plot" para cada par xy
set x 0
foreach y $list_error_prediction {
incr x
$s plot series1 $x $y
}
# Define o nome do gráfico
$s title "Graph Error prediction X Epoch"
$s xtext "Epoch"
$s ytext "Error"
A figura Z.27 mostra um exemplo de como pode variar o erro ao longo das scessivas etapas de treinamento (epoch).
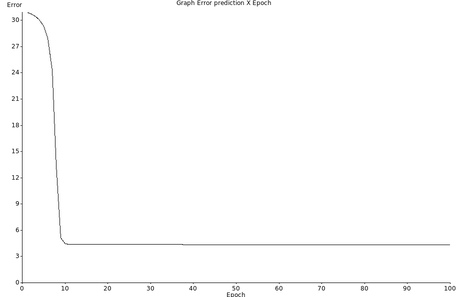
O treinamento da rede pode ser feito de duas formas:
Treinamento em “Batch” (Lote): também chamado aprendizado por ciclo no qual os erros são acumulados durante todo o conjunto de dados do Dataset (epoch) e só então é feito os ajustes nos pesos.
Treinamento “Incremental” (ou Padrão): também chamado aprendizado “on-line” ou por padrão, no qual o ajuste dos pesos é feito a cada “linha” do Dataset.
Z.2.9. Teste da Rede com o Dataset Iris Flower
Iris Flower é um dataset clássico que está disponível no repositório de “Machine Learning” da Universidade da California, Irvine (UCI) no link http://archive.ics.uci.edu/ml/machine-learning-databases/iris/.
Este conjunto de dados (Dataset) consiste em 50 amostras de cada uma das três espécies da flor Iris (Iris setosa, Iris virginica e Iris versicolor). Quatro características foram medidas a partir de cada amostra: o comprimento e a largura das sépalas e pétalas, em centímetros. O objetivo é treinar uma Rede Neural para ser capaz de identificar a espécie com base na combinação dessas quatro características.
Dica
Sobre datasets: https://en.wikipedia.org/wiki/Data_set#Classic_data_sets.
O arquivo iris.data, com 150 registros, possui a seguinte estrutura:
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
...
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
...
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
...
Para “ler” os quatro parâmetros de entrada a rede deve ter 4 neurônios na camada de entrada, mas a camada de saída poderia ter 1 ou 3 neurônios.
Poderíamos usar apenas um neurônio de saída assumindo valores numéricos discretos representando cada uma das três categorias (Ex: 1-setosa, 2-versicolor e 3-virginica).
Ou com 3 neurônios que poderiam assumir valores binários de 0 ou 1 para identificar as três categorias da seguinte forma:
1 0 0 -> Iris-setosa
0 1 0 -> Iris-versicolor
0 0 1 -> Iris-virginica
Decidimos implementar uma rede com 3 neurônios de saída e avaliar o efeito do número de camadas escondidas e o número de neurônios em diferentes camadas.
Mas antes de ler o Dataset é necessário “formatar” o arquivo para poder ser usado pela rede neural, e para isso implementamos o script format_data_iris.tcl:
#!/usr/bin/env tclsh
#format_data_iris.tcl
proc openDatasetFile { file_name } {
set channel [open $file_name r]
set dataset [read $channel]
close $channel
return $dataset
}
proc saveDatasetFile { file_name dataset } {
set channel [ open $file_name w ]
puts $channel $dataset
close $channel
}
set dataset [openDatasetFile iris.data]
set formated_dataset [regsub -all {\,} $dataset " "]
set formated_dataset [regsub -all {Iris-setosa} $formated_dataset "1 0 0"]
set formated_dataset [regsub -all {Iris-versicolor} $formated_dataset "0 1 0"]
set formated_dataset [regsub -all {Iris-virginica} $formated_dataset "0 0 1"]
saveDatasetFile formated_iris.data $formated_dataset
Este script converte o Dataset original iris.data substituindo a vírgula por espaço e o tipo de flor para o formato binário correspondente gerando o arquivo “formated_iris.data”:
5.1 3.5 1.4 0.2 1 0 0
4.9 3.0 1.4 0.2 1 0 0
4.7 3.2 1.3 0.2 1 0 0
4.6 3.1 1.5 0.2 1 0 0
...
7.0 3.2 4.7 1.4 0 1 0
6.4 3.2 4.5 1.5 0 1 0
6.9 3.1 4.9 1.5 0 1 0
5.5 2.3 4.0 1.3 0 1 0
...
6.3 3.3 6.0 2.5 0 0 1
5.8 2.7 5.1 1.9 0 0 1
7.1 3.0 5.9 2.1 0 0 1
6.3 2.9 5.6 1.8 0 0 1
Em seguida montamos inicialmente uma rede neural com 4 neurônios de entrada:
#Rede
set input_neurons {i1 i2 i3 i4}
Os neurônios da camada de entrada são indicados pela letra i (input) seguido de um índice numérico.
1 camada escondida com 3 neurônios:
#Criação das camadas escondidas (hidden) com os respectivos neurônios
dict set hidden_layers hidden_1 {1h1 1h2 1h3}
Cada camada escondida é idenficiada no formato hidden_N, onde N indica o número da camada e os neurônios são indicados no formato Nhn. Onde N corresponde ao número da camada, h corresponde a hidden e n é um índice numérico para cada neurônio.
E 3 neurônios na camada de saída:
#Lista dos neurônios na camada de saída
set output_neurons {o1 o2 o3}
Os neurônios da camada de saída são indicados pela letra o (output) seguido de um índice numérico.
Depois é definida a taxa de aprendizagem (learning rate):
#Define the learning rate set learning_rate 0.5
E os comandos para a criação da rede neural são executados:
#Criando a camada de entrada buildInputLayer rede_neural input_neurons #Criando a(s) camada(s) escondida(s) buildHiddenLayers rede_neural hidden_layers #Criando a camada de saída buildOutputLayer rede_neural output_neurons #Inicializando o weight com valores aleatórios entre 0 e 1 initWeight rede_neural ...
Em seguida ler o dataset e montar a lista de dados de entrada na variável input_list:
#Split the dataset in list of inputs with the parameters { dataset input_fields label (boolean) }
#input_fields is the number of fields of inputs
set input_list [readInputs $dataset {1 2 3 4} 0]
E os dados de saída na variável target_list:
#Split the dataset in list of targets with the parameters { dataset target_fields label (boolean) }
set target_list [readTargets $dataset { 5 6 7 } 0]
E fizemos o treinamento da rede por 500 ciclos (epoch):
set i 0
set list_error_prediction {}
while { $i < 500 } {
resetSumErrorPrediction
foreach input_record $input_list target_record $target_list {
puts "\n\nProcessing input_record: $input_record target_record: $target_record"
#set the inputs to the input neurons
if { ![writeInputs rede_neural $input_record] } { break }
#propagate the signal through the network
propagateInputs rede_neural
#print the signal of output neurons
printOutputs rede_neural
if { ![calcErrorOutputLayer rede_neural $target_record] } { break }
backPropagateError rede_neural
#Exibindo a rede
# printNeuralNetwork rede_neural
}
lappend list_error_prediction [getSumErrorPrediction]
incr i
}
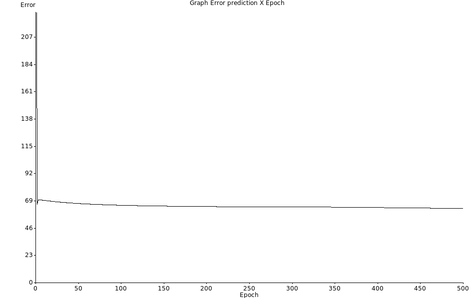
E erro apresentou queda até 100 “epochs” e permaneceu constante até o final do treinamento conforme a figura Z.28.
Figura Z.28. Gráfico de variação do erro de previsão ao longo dos ciclos de treinamento da rede neural com o dataset formated_iris.data
Para avaliar o efeito do número da camadas na eficiência de treinamento adicionei mais uma camada escondida:
set input_neurons {i1 i2 i3 i4}
#Criação das camadas escondidas (hidden) com os respectivos neurônios
dict set hidden_layers hidden_1 {1h1 1h2 1h3}
dict set hidden_layers hidden_2 {2h1 2h2 2h3}
#Lista dos neurônios na camada de saída
set output_neurons {o1 o2 o3}
#Define the learning rate
set learning_rate 0.5
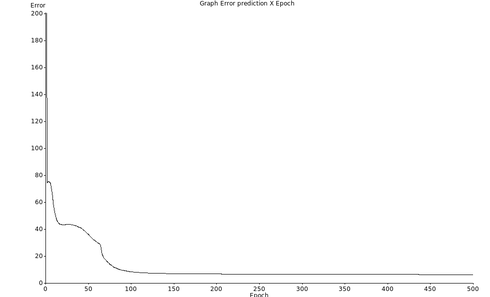
O erro chegou a um mínimo de ~60 e não reduziu mais como mostra a figura Z.29.
Figura Z.29. Gráfico de variação do erro de previsão ao longo dos ciclos de treinamento de uma rede com 2 camadas, de 3 neurônios, e o dataset formated_iris.data
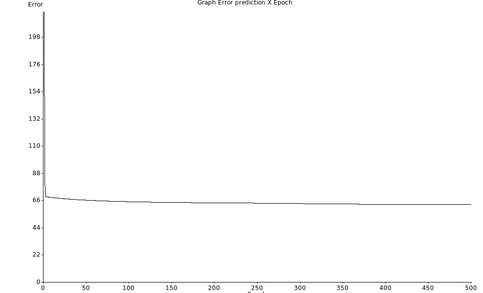
Repetimos o treinamento com duas camadas escondidas (3 neurônios cada), mas um novo conjunto inicial de pesos (aleatórios) e foi obtido um resultado semelhante (Figura Z.30).
Figura Z.30. Repetição do treinamento de uma rede, com novos pesos aleatórios, 2 camadas escondidas de 3 neurônios cada, e o dataset formated_iris.data
Adicionei uma terceira camada escondida:
set input_neurons {i1 i2 i3 i4}
#Criação das camadas escondidas (hidden) com os respectivos neurônios
dict set hidden_layers hidden_1 {1h1 1h2 1h3}
dict set hidden_layers hidden_2 {2h1 2h2 2h3}
dict set hidden_layers hidden_3 {3h1 3h2 3h3}
#Lista dos neurônios na camada de saída
set output_neurons {o1 o2 o3}
#Define the learning rate
set learning_rate 0.5
Mas após 500 epochs de treinamento o erro não melhorou.
Resolvi testar a eficiência de 1 camada escondida com 4 neurônios:
set input_neurons {i1 i2 i3 i4}
#Criação das camadas escondidas (hidden) com os respectivos neurônios
dict set hidden_layers hidden_1 {1h1 1h2 1h3 1h4}
#Lista dos neurônios na camada de saída
set output_neurons {o1 o2 o3}
#Define the learning rate
set learning_rate 0.5
E após 500 epochs de treinamento o erro chegou a 5,96.
Colocando mais um neurônio na camada escondida foi obtido um erro de 6,54.
Para conhecer um pouco mais as propriedades das redes neurais resolvi fazer vários treinamentos usando a rede com 1 camada de 6 neurônios e o mesmo dataset. Para isso fiz um primeiro treinamento e salvei a rede neural inicial (rede_neural_original.txt).
Em seguida comentei os comandos para criação de uma nova rede neural e deixei apenas o comando para abrir o arquivo rede_neural_original.txt:
#Criando a camada de entrada #buildInputLayer rede_neural input_neurons #Criando a(s) camada(s) escondida(s) #buildHiddenLayers rede_neural hidden_layers #Criando a camada de saída #buildOutputLayer rede_neural output_neurons #Inicializando o weight com valores aleatórios entre 0 e 1 #initWeight rede_neural #Inicializando o bias #initBias rede_neural 1 #Save the neural network structure in file #saveNeuralNetwork rede_neural rede_neural_original.txt #Unset the variable just to check commands save and open #unset rede_neural #Read the neural network from file set rede_neural [openNeuralNetwork rede_neural_original.txt]
Repeti o treinamento mais 2 vezes com 100 ciclos e obtivemos o mesmo gráfico de “erro x epoch” como mostra a figura Z.31.
Figura Z.31. Três repetições de treinamento usando a rede com 1 camada de 6 neurônios (rede_neural_original.txt), e o mesmo dataset (formated_iris.data).

Até agora fizemos o treinamento de diferentes configurações da rede para avaliar o efeito no treinamento.
Mas o correto é separar o conjundo de dados em dois grupos:
dados de treinamento: que serão utilizados para o treinamento da rede (50% a 80% do dataset original)
dados de teste: que serão utilizados para verificar sua performance sob condições reais de utilização.
Dica
Além dessa divisão, pode-se usar também uma subdivisão do conjunto de treinamento, criando um conjunto de validação, utilizado para verificar a eficiência da rede quanto à sua capacidade de generalização durante o treinamento, e podendo ser empregado como critério de parada do treinamento. (Fonte: http://conteudo.icmc.usp.br/pessoas/andre/research/neural/desenv.htm)
Para isso o dataset original foi dividido em dois grupos: training_iris_dataset.data e test_iris_dataset.data com o script:
#!/usr/bin/env tclsh
proc openDatasetFile { file_name } {
set channel [open $file_name r]
set dataset [read $channel]
close $channel
return $dataset
}
set dataset [openDatasetFile formated_iris.data]
set training_iris_dataset [open "training_iris_dataset.data" "w"]
set test_iris_dataset [open "test_iris_dataset.data" "w"]
set dataset_list [split $dataset "\n"]
set i 1
foreach line $dataset_list {
if {[expr $i % 2]} {
puts $training_iris_dataset $line
} else {
puts $test_iris_dataset $line
}
incr i
}
close $training_iris_dataset
close $test_iris_dataset
O arquivo training_iris_dataset.data foi usado para treinar a rede e o arquivo test_iris_dataset.data foi usado para calcular o “índice de acertos” da rede comparando os resultados previstos com os resultados experimentais.
Para o cálculo do “índice de acertos” implementei inicialmente um loop com o comando foreach que lê lê os dados de entrada (input_record) e de saída (target_record), escreve os dados de entrada nos neurônios de entrada, propaga o sinal através das camadas da rede e “simplesmente” verifica se o neurônio de saída com o “maior sinal” é o mesmo neurônio com maior sinal do arquivo de teste.
set i 0
set hit_rate 0
foreach input_record $input_list target_record $target_list {
puts "\n\nProcessing input_record: $input_record target_record: $target_record"
#set the inputs to the input neurons
if { ![writeInputs rede_neural $input_record] } { break }
#propagate the signal through the network
propagateInputs rede_neural
#print the signal of output neurons
set output_list [printOutputs rede_neural]
set output_list_w_comma [join $output_list ", "]
set min_output [expr min($output_list_w_comma)]
set max_output [expr max($output_list_w_comma)]
set pos_min_output [lsearch $output_list $min_output]
set pos_max_output [lsearch $output_list $max_output]
set target_record_w_comma [join $target_record ", "]
set min_target [expr min($target_record_w_comma)]
set max_target [expr max($target_record_w_comma)]
set pos_min_target [lsearch $target_record $min_target]
set pos_max_target [lsearch $target_record $max_target]
if {$pos_max_output == $pos_max_target} {
incr hit_rate
}
incr i
}
puts "\n$i records in test dataset"
puts "hit_rate: $hit_rate"
puts "hit_rate %: [expr ( $hit_rate / double($i) ) * 100.0]"
É um critério de acerto “pouco exigente”, mas o objetivo é ter uma idéia de como essa rede se comporta em uma atividade de classificação.
Registrei o índice de acertos (com o arquivo test_iris_dataset.data) e após sucessivas etapas de treinamento (com o arquivo training_iris_dataset.data) os resultados (Figura Z.32) mostram que os acertos chegam a 57 (76%) após 4000 ciclos de treinamento (epoch) e permanecem nesse nível até 50000 ciclos e chegam a diminuir para 56 (75%) com 100000 ciclos de treinamento.
Figura Z.32. Gráfico acertos x ciclos de treinamento (epoch) de uma rede com 1 camada escondida de 6 neurônios, e o dataset test_iris_dataset.data com 75 registros.
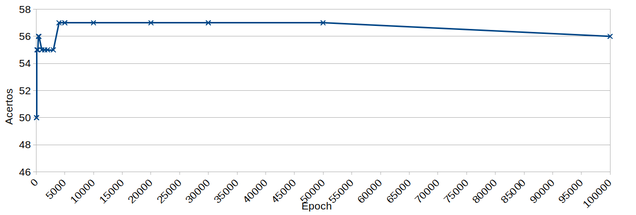
Figura Z.33. Gráfico do erro x ciclos de treinamento (epoch) de uma rede com 1 camada escondida de 6 neurônios, e o dataset test_iris_dataset.data com 75 registros
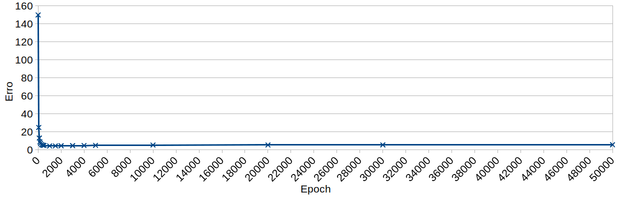
O erro é reduzido a um mínimo até ~1000 ciclos e permanece praticamente constante até 50000 ciclos.
Mas visualmente foi possível perceber que havia uma diferença no acertos para os 3 diferentes tipos de flor (Setosa, Versicolor e Virginica). E para quantificar essa diferença incluí alguns comandos no programa de teste para calcular o índice de acertos para cada tipo de flor:
...
#100
set hit_rate_iris_setosa 0
#010
set hit_rate_iris_versicolor 0
#001
set hit_rate_iris_virginica 0
...
if {$pos_max_output == $pos_max_target} {
incr hit_rate
if { $pos_max_target == 0 } {
incr hit_rate_iris_setosa
} elseif { $pos_max_target == 1 } {
incr hit_rate_iris_versicolor
} else {
incr hit_rate_iris_virginica
}
...
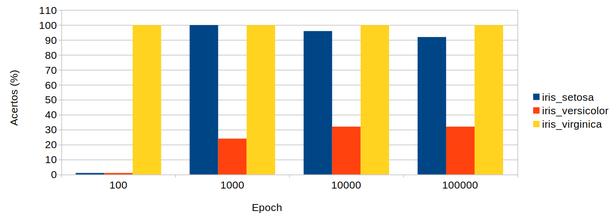
Foi possível constatar que o índice de acertos para a variedade versicolor era bem menor do que os outros dois grupos mesmo depois de sucessivos ciclos de treinamento como mostra a figura Z.34.
Figura Z.34. Gráfico acertos x ciclos de treinamento (epoch) de uma rede com 1 camada escondida de 6 neurônios, e o dataset test_iris_dataset.data com 75 registros.
Já estava quase desistindo mas resolvi investir na redução do número de camadas escondidas e de neurônios por camada. E depois de “várias” tentativas variando a taxa de aprendizado (lr), bias, número de camadas escondidas, número de neurônios por camada e o número de ciclos de treinamento (epoch), fiquei surpreso ao descobrir que os melhores resultados foram obtidos com uma rede contendo apenas 1 camada escondida com “2” neurônios. (Figura Z.35)
Figura Z.35. Gráfico acertos x ciclos de treinamento (epoch) de uma rede contendo 1 camada escondida com 2 neurônios, lr 0,1, bias 0,9, treinada com o dataset de treinamento training_iris_dataset.datae avaliada com o dataset de teste test_iris_dataset.data, ambos com 75 registros.
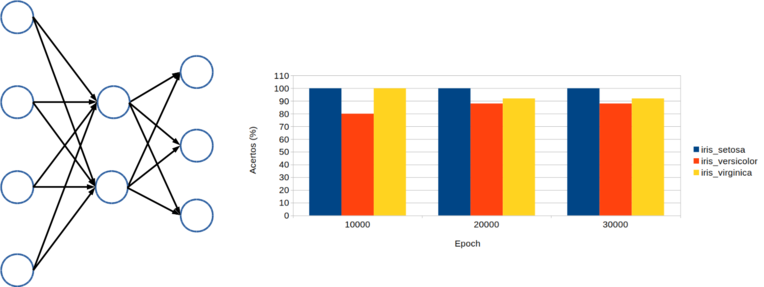
Após 10000 “epochs” com uma rede com 2 neurônios na camada escondida, lr=0,1 e bias=0,9 foram obtidos os seguintes resultados:
Rede neural treinada com 10000 epochs:
75 registros - 70 acertos (93,3%)
Iris Setosa 25 registros - 25 acertos (100%)
Iris Versicolor 25 registros - 20 acertos (80%)
Iris Virginica 25 registros - 25 acertos (100%)
Rede neural treinada com 20000 epochs:
75 registros - 70 acertos (93,3%)
Iris Setosa 25 registros - 25 acertos (100%)
Iris Versicolor 25 registros - 22 acertos (88%)
Iris Virginica 25 registros - 23 acertos (92%)
Com mais 10000 ciclos de treinamento o resultado global permaneceu o mesmo mas com uma pequena alteração nos acertos das classes Versicolor e Virginica.
Conclusões (parciais):
Esses estudos com o tema “Redes Neurais” foram muito úteis para entender “na prática” o funcionamento desse tipo de ferramenta.
Insisti no desenvolvimento da minha própria biblioteca (from scratch) como estratégia de aprendizagem mas pretendo, a partir de agora, conheceer melhor as bibliotecas “profissionais” para poder usar com mais eficiência e produtividade em futuros projetos ligados ao tema Água.
How to Implement the Backpropagation Algorithm From Scratch In Python
Gradiente Descendente - Um método poderoso e flexível para otimização iterativa.
Texto de referência que explica de forma didática o algoritmo para a retropropagação
How to Implement the Backpropagation Algorithm From Scratch In Python
How do I implement a simple neural network from scratch in Python?