Nesta seção vamos compartilhar algumas informações sobre o uso da biblioteca SQLite para a implementação de banco de dados em projetos de automação. O nosso objetivo é compartilhar dicas práticas de como usar essa biblioteca, mas sem entrar em detalhes teóricos sobre o “Modelo Relacional”.
A maior parte dessa seção foi retirada do livro The Definitive Guide to SQLite, 2010 e alguns trechos do livro Linux - Bancos de Dados, 1997.
Mas o que é um banco de dados?
Uma resposta simples: banco de dados é um corpo de dados organizados, e o software que o mantém. (Fonte: Linux - Bancos de Dados, 1997)
Porém, esta resposta traz duas perguntas a mais:
O que são dados?
E o que significa “manter um corpo de dados”?
Nota
Dado pode ser definido como um símbolo que descreve um aspecto de uma entidade ou evento no mundo real. E como “mundo real” podemos considerar o mundo cotidiano através do qual experimentamos os nossos 5 sentidos e falamos com linguagem comum. (Fonte: Linux - Bancos de Dados, 1997)
Por exemplo, um livro é uma entidade no mundo real que pode ser descrito pelos seguintes dados: título, número ISBN, autores, editor e o ano de publicação.
E para “manter um corpo de dados” é necessário executar as seguintes tarefas:
Estabelecer uma “caixa” para cada “categoria” de dados que serão armazenados.
Criar “compartimentos” em cada caixa para manter os dados, sendo um compartimento para cada “dado”.
Gerar uma identificação única para cada “caixa” e “compartimento” com informações sobre o conteúdo.
Produzir um catálogo descritivo das “caixas” e respectivos “compartimentos” para agilizar a consulta do conteúdo dos compartimentos.
Quando necessário adicionar novas “caixas” e “compartimentos”, e fazer as devidas atualizações no catálogo descritivo.
Se você acha que isso se parece com a descrição de um almoxarifado você está correto. Afinal tanto um almoxarifado quanto um banco de dados servem para organizar “coisas” que podem ser localizados com facilidade.
Um sistema de manutenção do banco de dados deve ser capaz de realizar as seguintes tarefas:
Organizar a estrutura de armazenamento dos dados.
Inserir os dados nas respectivas caixas e compartimentos.
Recuparar os dados “endereçados” nas respectivas caixas e compartimentos, e permitir o exame dos dados recuperados.
Apagar os dados utilizando os “endereços” das respectivas caixas e compartimentos.
Atualizar os dados do banco de dados.
Um sistema de banco de dados deve realizar essas 5 tarefas mas mantendo a “integridade dos dados”, ou seja, evitando erros que comprometem a “qualidade” (significado) dos dados.
Vários Sistemas de Gerenciamento de Banco de Dados (SGBD) foram desenvolvidos ao longo dos anos e nesta seção vamos utilizar um banco de dados relacional.
O modelo relacional foi proposto por Edgar F. Codd, um matemático da IBM em um documento publicado em 19 de agosto de 1969. Em 1974 a IBM iniciou o projeto “System/R” para construir um protótipo do sistema de banco de dados relacional. Como parte desse projeto foi criada uma linguagem de consulta para manipulação dos dados a qual foi chamada de “SEQUEL”. Mais tarde esta linguagem passou a ser chamada de SQL ou Structured Query Language (Linguagem de Consulta Estruturada).
Existem várias opções de sistemas de bancos de dados (SGBD) livres e comerciais, dentre os quais podemos citar o MySQL, PostgreSQL e o SQLite.
O SQLite é uma pequena biblioteca escrita em C que implementa um banco de dados SQL completo, embutido e sem configurações. (Fonte: SQLite Brasil).
Para começar a usar o SQLite instalamos o pacote necessário com o comando:
apt-get install sqlite3
Para executar o programa via linha de comando basta digitar em um terminal sqlite3.
E para seguir os exemplos do livro The Definitive Guide to SQLite, 2010 usamos o banco de dados disponibilizado pelo autor no link https://github.com/Apress/def-guide-to-sqlite-10/archive/master.zip.
Após baixar o arquivo “zip”, descompactamos (unzip), localizamos e copiamos o arquivo foods.sql para o diretório sqlite e criamos o banco de dados com o comando:
sqlite3 foods.db < foods.sql
O arquivo foods.sql é um script com um sequência de comandos SQL que são interpretados pelo programa sqlite3 para a criação do banco de dados foods.db com os nomes de aproximadamente 400 pratos citados ao longo de 180 episódios do seriado Seinfeld.
Parte do arquivo foods.sql:
BEGIN TRANSACTION; CREATE TABLE episodes ( id integer primary key, season int, name text ); INSERT INTO "episodes" VALUES(0, NULL, 'Good News Bad News'); INSERT INTO "episodes" VALUES(1, 1, 'Male Unbonding'); INSERT INTO "episodes" VALUES(2, 1, 'The Stake Out'); INSERT INTO "episodes" VALUES(3, 1, 'The Robbery'); INSERT INTO "episodes" VALUES(4, 1, 'The Stock Tip'); INSERT INTO "episodes" VALUES(5, 2, 'The Ex-Girlfriend'); . . .
A figura P.1 mostra a estrutura das tabelas do banco de dados foods.db:
Figura P.1. Estrutura das tabelas do banco de dados foods.db. (Fonte: The Definitive Guide to SQLite, 2010)

E são criadas com os comandos:
CREATE TABLE episodes ( id integer PRIMARY KEY, season int, name text ); CREATE TABLE foods( id integer PRIMARY KEY, type_id integer, name text ); CREATE TABLE food_types( id integer PRIMARY KEY, name text ); CREATE TABLE foods_episodes( food_id integer, episode_id integer );
O banco de dados é carregado pelo programa sqlite com o comando:
~/sqlite$ sqlite3 foods.db
E em seguida alguns comandos para formatar a saída são executados no prompt do programa SQLite:
sqlite> .echo on sqlite> .mode column sqlite> .headers on sqlite> .nullvalue NULL
Nota
E para sair do programa basta digitar o comando .exit:
sqlite> .exit
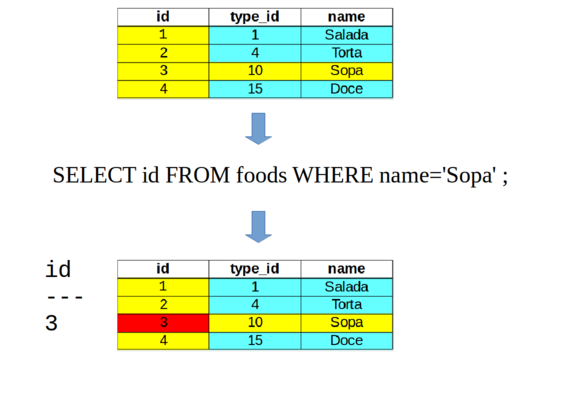
E para testar fizemos uma consulta:
sqlite> SELECT *
...> FROM foods
...> WHERE name='JujyFruit'
...> AND type_id=9;
SELECT *
FROM foods
WHERE name='JujyFruit'
AND type_id=9;
id type_id name
---------- ---------- ----------
244 9 JujyFruit
sqlite>
A sintaxe declarativa do SQL é semelhante a uma linguagem natural. As declarações são expressas no modo imperativo, começando com o verbo, que descreve a ação, seguido do sujeito e do predicado, como ilustrado na figura P.2

Uma linguagem declarativa é aquela em que você descreve apenas o “que” deseja, enquanto uma linguagem imperativa especifica “como” obter o resultado desejado.
Uma “declaração” representa um “comando” e é delimitada por “;”. E cada comando é composto por uma sequência de símbolos (tokens). (Fonte: Sintaxe da linguagem SQL)
Sequência de três comandos válidos:
select id, name from foods; insert into foods values (null, 'Whataburger'); delete from foods where id=413;
Um símbolo pode ser uma palavra-chave, um identificador, identificador entre aspas, um literal (ou constante), ou um caractere especial, e são geralmente separados por espaço em branco (espaço, tabulação ou nova-linha).
Literais, também chamados de constantes, denotam valores explícitos e podem ser de três tipos:
literal de cadeia (string) ('Jerry' 'Newman' 'JujyFruit')
literal numérico: inteiro, decimal ou em notação científica (-1 3.14 6.02E23)
literal binário: notação x'0000' (x'01' x'0fff' x'0F0EFF')
As palavras-chave (keyword) são palavras que têm um significado específico para a SQL tais como: SELECT, UPDATE, INSERT, CREATE, DROP e BEGIN.
Os identificadores são usados para referenciar os elementos do banco de dados: como tabelas, índices, registros (linhas) ou atributos (colunas).
Palavras-chave são palavras reservadas e não podem ser usadas como identificadores.
A SQL não faz distinção entre letras maiúsculas e minúsculas para as palavras-chave e os identificadores, e portanto as instruções a seguir são equivalentes:
SELECT * from food;
SeLeCt * FrOm FOOD;
Nota
No entanto é comum digitar as palavras-chave da SQL com letras maiúsculas e digitar os nomes da tabela e da coluna com letras minúsculuas, mas isto não é obrigatório.
O comentários podem ser precedidos por “--” ou delimitados por “/*” e “*/”:
-- Comentário em uma linha
/* Comentário em
duas linhas */
Agora vamos ver com mais detalhes as operações básicas de um banco de dados com o SQLite.
A “tabela”, formada por linhas e colunas, é a unidade padrão de informação em um banco de dados relacional e a estrutura do comando para a criação de uma tabela é:
CREATE TABLE nome_tabela ( nome_coluna domínio, ..., [, restrições] );
O comando CREATE TABLE necessita de um nome para a tabela (nome_tabela) e os nomes das colunas (nome_coluna), separados por vírgulas, que vão compor a tabela seguidos dos “domínios”.
O domínio significa o “tipo” do dado que será armazenado na coluna que pode ser: integer, real, text, blob ou null. (Fonte: Datatypes In SQLite)
E finalmente uma lista de “restrições” (constraints) também separada por vírgulas que visa manter a consistência (ou integridade) dos dados. As restrições podem ser: (Fonte: O que é uma Constraint?)
PRIMARY KEY (PK) - cria um índice único para um conjunto de colunas ou uma coluna para Chave Primaria.
UNIQUE - determina que uma coluna não poderá ter 2 linhas com o mesmo valor.
FOREIGN KEY (FK ou Chave Estrangeira) - Determina uma coluna ou um conjunto de colunas que possuem valores em outras tabelas, referente a uma referência ou um relacionamento.
CHECK - Especifica uma condição que a coluna precisa ter para salvar os dados.
NOT NULL - Determina que a coluna tem preenchimento obrigatório (não pode ser nula).
DEFAULT - Determina um valor default para a coluna.
Exemplo de criação de uma tabela:
CREATE TABLE agenda ( id integer PRIMARY KEY,
nome text NOT NULL COLLATE NOCASE,
fone text NOT NULL DEFAULT 'UNKNOWN',
UNIQUE (nome,fone) );
A coluna “id” é declarada para ter o tipo integer e a restrição de ser uma chave primária. Uma chave primária (PRIMARY KEY) com o tipo inteiro (integer) transforma a coluna em uma coluna de “autoincremento”.
A restrição PRIMARY KEY é uma combinação das restrições UNIQUE e NOT NULL.
A coluna nome é declarada como sendo do tipo text e tem duas restrições: NOT NULL (não nulo), COLLATE e NOCASE.
A restrição COLLATE permite definir como os campos do tipo text são comparados ao longo de uma coluna. E a associação com a restrição NOCASE permite impedir nomes semelhantes em uma mesma coluna. Por exemplo, se for inserido o contato 'Jerry' pela linha de comando no SQLite:
sqlite> insert into agenda (nome, fone) values ('Jerry', '555-1212');
Não será possível inserir outro contato com o nome 'JERRY':
sqlite> insert into agenda (nome, fone) values ('JERRY', '555-1212');
insert into agenda (nome, fone) values ('JERRY', '555-1212');
Error: UNIQUE constraint failed: agenda.nome, agenda.fone
Mas a inserção de 'JERRY' seria possível se não fosse inserido a restrição NOCASE no campo nome.
E a coluna fone é do tipo text e tem duas restrições: NOT NULL e DEFAULT. Isso significa que esse campo não pode ficar “vazio” (NULL) e se não for inserido um dado para esse campo o banco de dados insere automaticamente a string 'UNKNOWN'.
Depois disso, há uma restrição UNIQUE a qual define que nenhum valor repetido poderá ser fornecido para os campos nome e fone.
Para visualizar a estrutura da tabela basta digitar o comando .schema:
sqlite> .schema .schema CREATE TABLE agenda ( id integer PRIMARY KEY, nome text NOT NULL COLLATE NOCASE, fone text NOT NULL DEFAULT 'UNKNOWN', UNIQUE (nome,fone) );
Para alterar a estrutura da tabela e inserir novos campos existe o comando alter table:
sqlite> ALTER TABLE agenda ...> ADD COLUMN email text NOT NULL DEFAULT '' COLLATE NOCASE; sqlite> .schema CREATE TABLE agenda ( id integer PRIMARY KEY, nome text NOT NULL COLLATE NOCASE, fone text NOT NULL DEFAULT 'UNKNOWN', email text NOT NULL DEFAULT '' COLLATE NOCASE, UNIQUE (nome,fone) );
Agora que criamos as tabelas vamos analisar como inserir dados em uma tabela com o comando INSERT.
A primeira forma do comando INSERT permite inserir valores diretamente em uma tabela com a sintaxe:
INSERT INTO nome_da_tabela [(nome_da_coluna[, ...])] VALUES (valor[, ...])
A variável nome_da_tabela nomeia a tabela na qual os valores serão inseridos.
A cláusula nome_da_coluna (opcional) nomeia as colunas da tabela nome_da_tabela onde serão inseridos os valores. E todas as colunas não nomeadas nesta cláusula terão NULL inserido nelas.
Se não for usada a cláusula nome_da_coluna, a operação default será inserir um valor para cada coluna da tabela.
A cláusula VALUES fornecerá os valores que você está inserindo na tabela nome_da_tabela.
Deve haver um valor para cada coluna (campo) especificado pela cláusula nome_da_coluna, e se não tiver uma cláusula nome_da_coluna, como citado anteriormente, terá que ter um valor para cada coluna da tabela.
O tipo dos dados de cada “valor” deve estar de acordo com o tipo de dado especificado para a coluna na qual será inserido; por exemplo: você não poderá inserir uma string de texto (text) em uma coluna com o tipo de dado inteiro (integer).
Por exemplo: a declaração a seguir insere um novo registro na tabela foods:
sqlite> INSERT INTO foods (name, type_id) VALUES ('Cinnamon Bobka', 1);
Estrutura da tabela foods:
CREATE TABLE foods( id integer PRIMARY KEY, type_id integer, name text );
Esta declaração insere uma linha (registro) na tabela foods, especificando dois valores de coluna. O primeiro elemento da lista VALUES é a string 'Cinnamon Bobka' e corresponde ao nome da coluna name. Da mesma forma, o valor inteiro 1 corresponde à coluna type_id.
Observe que o campo id não foi mencionado. Nesse caso, o banco de dados usa o valor padrão. Como id foi declarado como chave primária (PRIMARY KEY) do tipo inteiro (integer), ele será gerado automaticamente e associado ao novo registro.
O novo registro pode ser visualizado com o comando SELECT, e o valor usado para id pode ser consultado também:
sqlite> INSERT INTO foods (name, type_id) VALUES ('Cinnamon Bobka', 1);
sqlite> SELECT * FROM foods WHERE name='Cinnamon Bobka';
id type_id name
---------- ---------- --------------
13 1 Cinnamon Bobka
413 1 Cinnamon Bobka
Já havia um registro com name 'Cinnamon Bobka' e id 13, e o novo registro aparece com id 413.
Inserindo um novo registro apenas na coluna name:
sqlite> INSERT INTO foods (name) VALUES ('Cinnamon Bobka');
sqlite> SELECT * FROM foods WHERE name='Cinnamon Bobka';
id type_id name
---------- ---------- --------------
13 1 Cinnamon Bobka
413 1 Cinnamon Bobka
414 NULL Cinnamon Bobka
Nesse caso a coluna type_id recebe NULL.
E como citado anteriormente, se não for usada a cláusula nome_da_coluna, a operação default será inserir um valor para cada coluna da tabela:
sqlite> INSERT INTO foods VALUES(NULL, 1, 'Chocolate Bobka'); sqlite> SELECT * FROM foods WHERE name like '%Bobka'; id type_id name ---------- ---------- --------------- 10 1 Chocolate Bobka 13 1 Cinnamon Bobka 413 1 Cinnamon Bobka 414 NULL Cinnamon Bobka 415 1 Chocolate Bobka
Observe que a string 'Chocolate Bobka' foi colocada depois do campo type_id para respeitar a estrutura da tabela foods, que pode ser visualizada com o comando .schema:
sqlite> .schema foods CREATE TABLE foods( id integer PRIMARY KEY, type_id integer, name text );
A primeira coluna é o id, seguida por type_id e em seguida name. Portanto essa deve ser a ordem dos valores em declarações de inserção na tabela foods.
E porque o campo id recebeu “NULL”?
O campo id foi definido como PRIMARY KEY e ao receber NULL dispara o recurso de “autoincremento” gerando automaticamente uma chave.
Nota
Mas o que significa “NULL”?
Algumas vezes, os dados estão faltando devido a um erro ou a uma falha humana: uma pessoa não digitou todas as informações necessárias no sistema ou as informações disponíveis não se aplicam exatamente à entidade ou evento que o registro descreve.
Para lidar com essas situações, o modelo relacional introduz a noção do NULL
NULL não é exatamente um valor, mas um símbolo que indica que um determinado dado não é conhecido. E o modelo relacional garante que NULL não irá coincidir com nenhum dado, independente do seu valor: NULL não irá coincidir nem mesmo com NULL.
Por exemplo: apesar do registro com id=414 ter type_id=NULL, se tentarmos fazer uma consulta com type_id=NULL não teremos qualquer retorno:
sqlite> SELECT * FROM foods WHERE type_id=NULL; sqlite>
Para consultar o id do último registro podemos usar “max(id)” ou “last_insert_rowid()”:
sqlite> select max(id) from foods; max(id) ---------- 415 sqlite> select last_insert_rowid(); last_insert_rowid() ------------------- 415
A segunda forma do comando INSERT permite a transferência de valores de uma ou mais tabelas para uma outra tabela com a sintaxe:
INSERT INTO nome_da_tabela [(nome_da_coluna[, ...])] SELECT declaração_de_seleção
Esta forma do comando INSERT pode substituir uma parte da lista da cláusula VALUES por um comando SELECT ou até mesmo toda a cláusula VALUES.
O comando SELECT “seleciona” os dados de uma tabela que serão posteriormente inseridos na tabela nome_da_tabela.
Por exemplo, a declaração seguinte insere apenas 1 linha, selecionada da tabela food_types e insere na tabela foods:
sqlite> INSERT INTO foods ...> VALUES (NULL, ...> (SELECT id FROM food_types WHERE name='Bakery'), ...> 'Blackberry Bobka'); sqlite> SELECT * FROM foods WHERE name like '%Bobka'; id type_id name ---------- ---------- --------------- 10 1 Chocolate Bobka 13 1 Cinnamon Bobka 413 1 Cinnamon Bobka 414 NULL Cinnamon Bobka 415 1 Chocolate Bobka 416 1 Blackberry Bobk
E no exemplo seguinte a declaração “SELECT null, type_id, name FROM foods WHERE name LIKE '%Bobka'” seleciona todos os registros da tabela foods que possuem a string “Bobka” no campo nome. E a declaração “INSERT INTO foods” insere na mesma tabela o resultado da seleção anterior:
sqlite> INSERT INTO foods ...> SELECT null, type_id, name FROM foods ...> WHERE name LIKE '%Bobka'; sqlite> SELECT * FROM foods WHERE name like '%Bobka'; id type_id name ---------- ---------- --------------- 10 1 Chocolate Bobka 13 1 Cinnamon Bobka 413 1 Cinnamon Bobka 414 NULL Cinnamon Bobka 415 1 Chocolate Bobka 416 1 Blackberry Bobk 417 1 Chocolate Bobka 418 1 Cinnamon Bobka 419 1 Cinnamon Bobka 420 NULL Cinnamon Bobka 421 1 Chocolate Bobka 422 1 Blackberry Bobk
Podemos usar esse recurso para criar uma nova tabela (foods_copy) e “preencher” a nova tabela com os dados da tabela original:
sqlite> CREATE TABLE foods_copy (id int, type_id int, name text); sqlite> INSERT INTO foods_copy SELECT * FROM foods; sqlite> SELECT count(*) FROM foods; count(*) ---------- 422 sqlite> SELECT count(*) FROM foods_copy; count(*) ---------- 422
Como dissemos anteriormente o objetivo de um banco de dados é armazenar dados e disponibilizar ferramentas para a consulta “seletiva” de dados com base em “critérios específicos de filtragem”.
A linguagem SQL possui o comando SELECT para a realização de consultas, o qual permite: coletar, combinar, comparar e filtrar os dados organizados nas tabelas de um banco de dados.
O comando SELECT em sua forma mais simples tem a seguinte sintaxe:
SELECT nome_da_coluna[, ...] FROM nome_da_tabela

A variável nome_da_coluna define a(s) coluna(s) da tabela nome_da_tabela.
Por exemplo, a tabela foods possui 3 colunas (id, type_id, e name):
sqlite> .schema foods CREATE TABLE foods( id integer primary key, type_id integer, name text );
O comando SELECT na declaração seguinte filtra apenas as colunas id e name da tabela foods:
sqlite> SELECT id, name FROM foods; id name ---------- ---------- 1 Bagels 2 Bagels, ra 3 Bavarian C 4 Bear Claws 5 Black and 6 Bread (wit 7 Butterfing 8 Carrot Cak 9 Chips Ahoy 10 Chocolate ...
Essa declaração gera uma saída com 422 linhas mas exibimos apenas as 10 primeiras.
Para selecionar “todas” as colunas da tabela basta substituir o(s) nome(s) da(s) coluna(s) pelo caracter “*”:
sqlite> SELECT * FROM foods; id type_id name ---------- ---------- ---------- 1 1 Bagels 2 1 Bagels, ra 3 1 Bavarian C 4 1 Bear Claws 5 1 Black and 6 1 Bread (wit 7 1 Butterfing 8 1 Carrot Cak 9 1 Chips Ahoy 10 1 Chocolate ...
A declaração “SELECT nome_da_coluna[, ...] FROM nome_da_tabela” permite filtrar “colunas” de uma tabela.
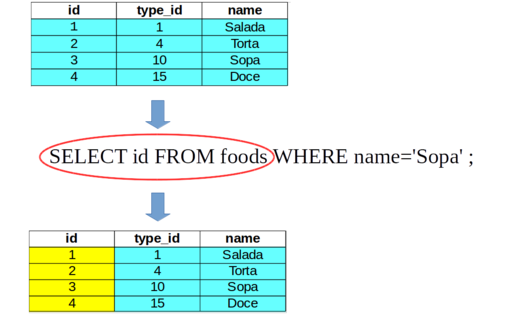
E como podemos filtrar “linhas”?
Essa operação pode ser feita com a cláusula restritiva WHERE com a seguinte sintaxe:
SELECT nome_da_coluna[, ...] FROM nome_da_tabela [WHERE expressão_de_restrição]

A SQLite aplica a cláusula WHERE a cada linha da tabela que é obtida pela aplicação da cláusula FROM.
Explicando de outra forma.
O argumento de WHERE é um “predicado lógico”. Um predicado, no sentido mais simples, é apenas uma afirmação sobre algo. Considere a seguinte declaração:
A flor (sujeito) é amarela e tem pétalas pequenas (predicado).
A flor é o sujeito, e o predicado é formado por duas afirmações (a cor é amarela e as pétalas são pequenas) que podem ser verdardeiras ou falsas.
O sujeito em uma cláusula WHERE é uma linha da tabela. A linha é o sujeito lógico, e a cláusula WHERE é o predicado lógico.
Cada linha na qual a afirmação é avaliada como verdadeira é incluída (ou selecionada) como parte do resultado, e cada linha em que a afirmação é falsa é excluída. Assim, a proposição sobre a flor traduzida para uma declaração relacional ficaria:
SELECT * FROM flores WHERE cor='amarela' and pétala='pequena';
O banco de dados aplica em cada linha da tabela flores (o sujeito) a cláusula WHERE (predicado) para formar uma proposição lógica:
Esta linha tem cor='amarela' e pétala='pequena'.
Se for verdadeira será incluída na tabela resultante, senão será excluída.
Como já dito anteriormente, o comando SELECT inclui a cláusula WHERE que implementa uma operação de “restrição”:
SELECT nome_da_coluna[, ...] FROM nome_da_tabela [WHERE expressão_de_restrição]
Uma “expressão” é uma frase do código que usa um operador para modificar uma constante, o nome da coluna ou o produto de uma outra expressão para calcular um valor que o programa usa para controlar a seleção dos dados de um banco de dados.
Vamos fazer alguns comentários sobre dois elementos que compõem uma expressão: as constantes e os operadores.
As constantes podem ser de 3 tipos diferentes: numérica, string e data/hora.
As constantes numéricas pode ser do tipo “inteiro” (1, 15, -273) ou com “ponto flutuante” (real) (1.0, 3.14, 7.15E-8).
Regras para operações aritméticas:
Aritmética com duas constantes inteiras = resultado inteiro (integer)
Aritmética com duas constantes real = resultado real
Aritmética com integer e real = resultado real
Comparação de integer apenas com uma coluna com tipo integer também
Comparação de real apenas com uma coluna com tipo real também
Uma constante de data/hora é uma string que descreve uma data ou uma hora. No entanto SQLite não tem um tipo de dado reservado para armazenar datas e/ou horas. Em vez disso, as Funções de data e hora incorporadas do SQLite são capazes de armazenar datas e horas como valores TEXT, REAL ou INTEGER (Fonte: Datatypes In SQLite)
Funções do SQLite para data e hora: (Fonte: Date And Time Functions)
sqlite> SELECT date(); date() ---------- 2017-02-06 sqlite> SELECT time(); time() ---------- 15:52:32 qlite> SELECT datetime(); datetime() ------------------- 2017-02-06 16:06:19 sqlite> SELECT current_date; current_date ------------ 2017-02-06 sqlite> SELECT current_time; current_time ------------ 15:52:58 sqlite> SELECT current_timestamp; current_timestamp ------------------- 2017-02-06 16:07:12
Exemplo de uso das funções de data e hora:
sqlite> .headers on sqlite> .mode column sqlite> .nullvalue NULL sqlite> CREATE TABLE data_hora ( id int, ...> data NOT NULL DEFAULT current_date, ...> hora NOT NULL DEFAULT current_time, ...> data_hora NOT NULL DEFAULT current_timestamp ); sqlite> INSERT INTO data_hora (id) values (1); sqlite> INSERT INTO data_hora (id) values (2); sqlite> SELECT * FROM data_hora; id data hora data_hora ---------- ---------- ---------- ------------------- 1 2017-02-07 11:28:51 2017-02-07 11:28:51 2 2017-02-07 11:29:10 2017-02-07 11:29:10 sqlite>
Um Operador recebe um ou mais valores de entrada e produz um valor de saída. Ou seja, executa uma operação produzindo algum tipo de resultado.
Quando operam sobre apenas um valor de entrada (ou operando) são chamados de “unários”. Os operadores “binários” recebem dois valores de entrada, e os operadores ternários recebem três operandos.
Os operadores podem ser encadeados em expressões onde a saída de um é a entrada de outro conforme o diagrama da figura P.1.
Figura P.7. Encadeamente de operadores unário, binário e ternário formando uma expressão. (Fonte: The Definitive Guide to SQLite, 2010)
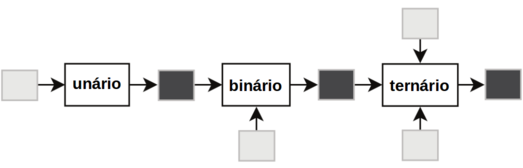
Os operadores são usados para especificar condições em uma declaração SQLite e servir como conjunção para “encadear” várias condições em uma declaração. (Fonte: What is an Operator in SQLite?)
Basicamente podem ser de dois tipos: aritméticos e lógicos. Um operador aritmético produz uma saída numérica, ao passo que um operador lógico produz um resultado lógico (TRUE, FALSE ou NULL) e permitem formar “expressões lógicas”.
Operadores unários suportados pela SQLite: “-”, “+”, “~” e “NOT”.
Operadores binários suportados pela SQLite em ordem decrescente de precedência: (Fonte: SQL As Understood By SQLite)
|| (concatenação de string)
“*” (operador aritmético multiplicação), “/” (operador aritmético divisão) e “%” (operador aritmético módulo - resto da divisão)
“+” (operador aritmético soma) e “–” (operador aritmético subtração)
“≪” (operador bit-a-bit(bitwise) deslocamento à esquerda) , “≫” (operador bit-a-bit(bitwise) deslocamento à direita), “&” (operador lógico and) e “|” (operador lógico ou)
“<” (operador relacional menor que), “<=” (operador relacional menor ou igual que), “>” (operador relacional maior que) e “>=” (operador relacional maior ou igual que)
“=” (operador relacional igual), “==” (operador relacional igual), “!=” (operador relacional não igual (diferente)), “<>” (operador relacional não igual (diferente)), “IS” (operador lógico igual), “IS NOT” (operador lógico desigual), “IN” (operador lógico em), “LIKE” (operador relacional correspondência de string) e “GLOB” (operador relacional correspondência de nome de arquivo)
“AND” (operador lógico and)
“OR” (operador lógico ou)
Como já dito anteriormente, um operador aritmético produz uma saída numérica, ao passo que um operador lógico produz um resultado lógico (TRUE, FALSE ou NULL) e permitem formar “expressões lógicas”.
No SQLite FALSE é representado pelo número “0” enquanto TRUE é representado por qualquer outro número diferente de 0.
sqlite> SELECT 1 > 2; 1 > 2 ---------- 0 sqlite> SELECT 1 < 2; 1 < 2 ---------- 1 sqlite> SELECT 1 = 2; 1 = 2 ---------- 0
Exemplo de uso do operador lógico:
qlite> SELECT * FROM foods WHERE name='JujyFruit' AND type_id=9; id type_id name ---------- ---------- ---------- 244 9 JujyFruit sqlite> SELECT * FROM foods WHERE id >= 1 AND id <= 10; id type_id name ---------- ---------- ---------- 1 1 Bagels 2 1 Bagels, ra 3 1 Bavarian C 4 1 Bear Claws 5 1 Black and 6 1 Bread (wit 7 1 Butterfing 8 1 Carrot Cak 9 1 Chips Ahoy 10 1 Chocolate
O operador relacional LIKE é usado apenas com strings e serve para verificar se uma string coincide com um determinado padrão de strings. Por exemplo, para selecionar todas as linhas em alimentos cujos nomes começam com a letra J, você pode fazer o seguinte:
sqlite> SELECT id, name FROM foods WHERE name LIKE 'J%'; id name ---------- ---------- 156 Juice box 236 Jucyfruit 243 Jello with 244 JujyFruit 245 Junior Min 370 Jambalaya
O caracter curinga “%” no padrão corresponde a qualquer sequência de zero ou mais caracteres na string.
O SQLite reconhece dois caracteres curingas:
% - coincide zero ou mais caracteres
_ - coincide com qualquer caractere único na string
Dica
Comparando com o shell do Linux o “%” é equivalente ao “*” e o “_” é equivalente ao “?”.
O operador relacional GLOB é muito semelhante em comportamento ao operador LIKE. Sua principal diferença é que ele se comporta de forma semelhante à semântica do “globbing” no Linux. Isso significa que ele usa os caracteres universais associados ao globbing de arquivos, como “*” e “?” (wildcards) e discrimina entre maiúsculas e minúsculas.
O exemplo a seguir mostra o uso do glob:
sqlite> SELECT id, name FROM foods ...> WHERE name GLOB 'Pine*'; id name ---------- ---------- 205 Pineapple 258 Pineapple
O operador BETWEEN é logicamente equivalente a um par de comparações. "x BETWEEN y AND z" é equivalente a "x >= y AND x <= z", exceto que com BETWEEN, a expressão x só é avaliada uma vez.
sqlite> SELECT * FROM foods WHERE id BETWEEN 10 AND 20; id type_id name ---------- ---------- --------------- 10 1 Chocolate Bobka 11 1 Chocolate Eclai 12 1 Chocolate Cream 13 1 Cinnamon Bobka 14 1 Cinnamon Swirls 15 1 Cookie 16 1 Crackers 17 1 Cupcake 18 1 Cupcakes 19 1 Devils Food Cak 20 1 Dinky Donuts
O operador IN verifica se o valor de uma coluna coincide com qualquer valor em uma lista.
Exemplo de uso:
sqlite> SELECT * FROM foods
...> WHERE name IN ('Brocolli', 'Carrots', 'Oranges');
id type_id name
---------- ---------- ----------
202 8 Oranges
385 15 Brocolli
387 15 Carrots
O operador IS não é exatamente um operador, mas serve especificamente para verificar se uma determinada coluna está definida para NULL. O NULL não é um valor, mas sim um “flag” (marca) que indica a ausência de um valor. Este operador verifica se uma variável é ou não NULL retornando TRUE ou FALSE conforme o caso.
Exemplo de uso:
sqlite> SELECT id, type_id, name FROM foods ...> WHERE type_id IS NULL; id type_id name ---------- ---------- -------------- 414 NULL Cinnamon Bobka 420 NULL Cinnamon Bobka
Até o momento os dados selecionados a partir do banco de dados apareceram na ordem em que foram inseridos. Porém o comando SELECT inclui uma cláusula ORDER BY com a qual é possível classificar a saída de uma seleção na ordem crescente ou decrescente, com a sintaxe:
>
SELECT nome_da_coluna | constante | expressão aritmética [,...]
FROM nome_da_tabela[,...]
[WHERE [expressão_de_restrição][expressão_de_junção]]
[ORDER BY nome_da_coluna[ASC|DESC][,...][ASC|DESC]]
Exemplo de uso:
sqlite> .width 5 5 25 sqlite> SELECT * FROM foods ...> WHERE name like 'Ba%' ...> ORDER BY type_id DESC; id type_ name ----- ----- ------------------------- 382 15 Baked Beans 383 15 Baked Potato w/Sour Cream 327 12 Bacon Club (no turkey) 274 10 Bacon 192 8 Banana 108 5 Banana Yogurt 87 4 Barbeque Sauce 1 1 Bagels 2 1 Bagels, raisin 3 1 Bavarian Cream Pie
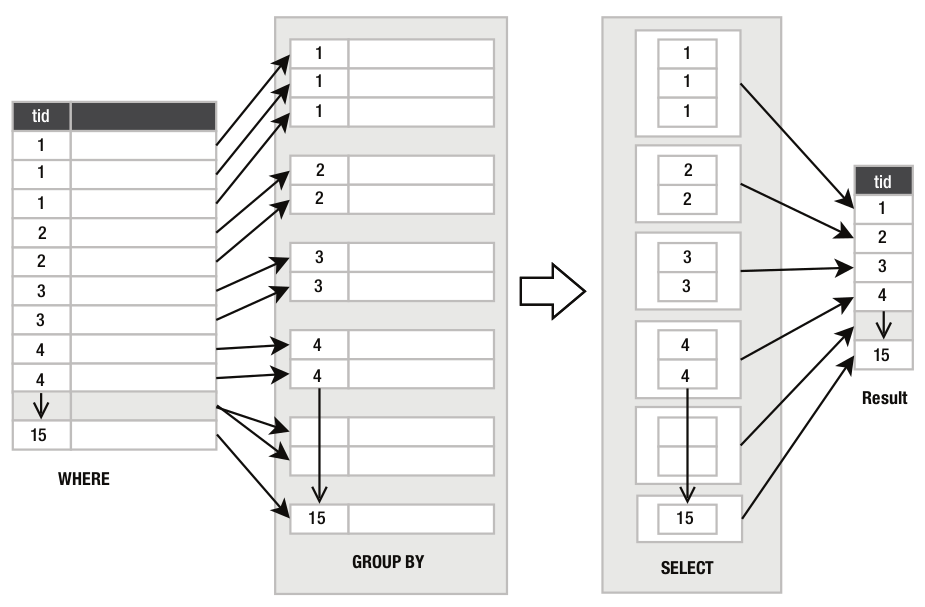
A clausula GROUP BY permite organizar a saída de um comando SELECT em grupos de dados idênticos.
A sintaxe consiste em colocar após “GROUP BY” os nomes de uma ou mais colunas separadas por vírgulas. O interpretador do SQLite irá agrupar a saída segundo os valores das colunas, na ordem em que foram nomeadas.
Exemplo de uso:
qlite> SELECT type_id FROM foods GROUP BY type_id; type_id ---------- NULL 1 2 3 . . . 15
GROUP BY é usada entre a cláusula WHERE e o comando SELECT, e divide a saída de WHERE em grupos de linhas que possuem um valor (ou valores) em comum para uma coluna (ou colunas) específica. E esses grupos de linhas são então repassados para o comando SELECT.
No exemplo anterior, existem 15 diferentes tipos de alimentos (type_id varia de 1 a 15) e por isso GROUP BY organiza todas as linhas da tabela foods em 15 grupos segundo o type_id. Em seguida o comando SELECT recebe cada grupo, extrai o valor comum de type_id e coloca em uma linha separada gerando por isso uma saída de 15 linhas, uma para cada grupo conforme o diagrama da figura P.8.
Figura P.8. Estrutura de funcionamento da cláusula GROUP BY para o exemplo anterior. (Fonte: The Definitive Guide to SQLite, 2010)
Exibindo o número de elementos (linhas) em cada grupo:
sqlite> SELECT type_id, count(*) FROM foods GROUP BY type_id; type_id count(*) ---------- ---------- NULL 2 1 55 2 15 3 23 4 22 5 17 6 4 7 60 8 23 9 61 10 36 11 16 12 23 13 14 14 19 15 32
Nesse último exemplo a função count(*) foi usada 15 vezes (uma para cada grupo), como mostra a figura P.9.
Nota
O diagrama não mostra todas as linhas (registros) de cada grupo e não indica o grupo com type_id=NULL.
Figura P.9. Aplicação da função count(*) associada à cláusula GROUP BY. (Fonte: The Definitive Guide to SQLite, 2010)
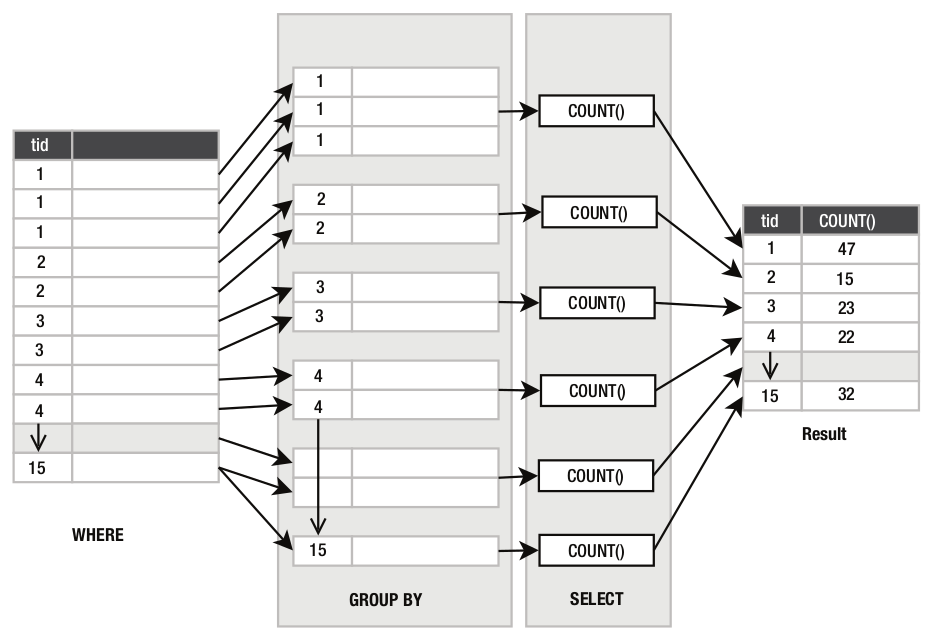
Sem o uso do GROUP BY essa informação poderia ser obtida fazendo 15 consultas:
qlite> SELECT count(*) FROM foods WHERE type_id=null; count(*) ---------- 0 sqlite> SELECT count(*) FROM foods WHERE type_id IS null; count(*) ---------- 2 sqlite> SELECT count(*) FROM foods WHERE type_id=1; count(*) ---------- 55 sqlite> SELECT count(*) FROM foods WHERE type_id=2; count(*) ---------- 15 . . . sqlite> SELECT count(*) FROM foods WHERE type_id=15; count(*) ---------- 32
Dica
Lembrar que para consultar campos contendo NULL deve ser usada o “operador” IS.
A cláusula GROUP BY faz o agrupamento dos registros e transfere o resultado para o comando SELECT, mas também é possível fazer uma “filtragem” desses grupos antes de transferir para o comando SELECT.
Isso pode ser feito com o predicado HAVING.
Por exemplo, vamos refazer a consulta do exemplo anterior mas dessa vez vamos selecionar apenas os grupos de alimentos com menos de 20 itens:
sqlite> SELECT type_id, count(*) FROM foods ...> GROUP BY type_id HAVING count(*) < 20; type_id count(*) ---------- ---------- NULL 2 2 15 5 17 6 4 11 16 13 14 14 19
O predicado HAVING é aplicado ao resultado da cláusula GROUP BY e faz uma filtragem análoga á filtragem da cláusula WHERE sobre a saída da cláusuala FROM.
A diferença é que o predicado da cláusula WHERE é expresso em termos de valores individuais de cada linha enquanto que o predicado de HAVING é expresso em termos de valores “agregados”.
Neste exemplo HAVING aplica o predicado count(*)<20 a todos os grupos, e somente os grupos que satisfazem a essa condição são passados para o comando SELECT conforme o diagrama da figura P.10.
Figura P.10. Aplicação da função count(*) associada à cláusula GROUP BY e HAVING. (Fonte: The Definitive Guide to SQLite, 2010)
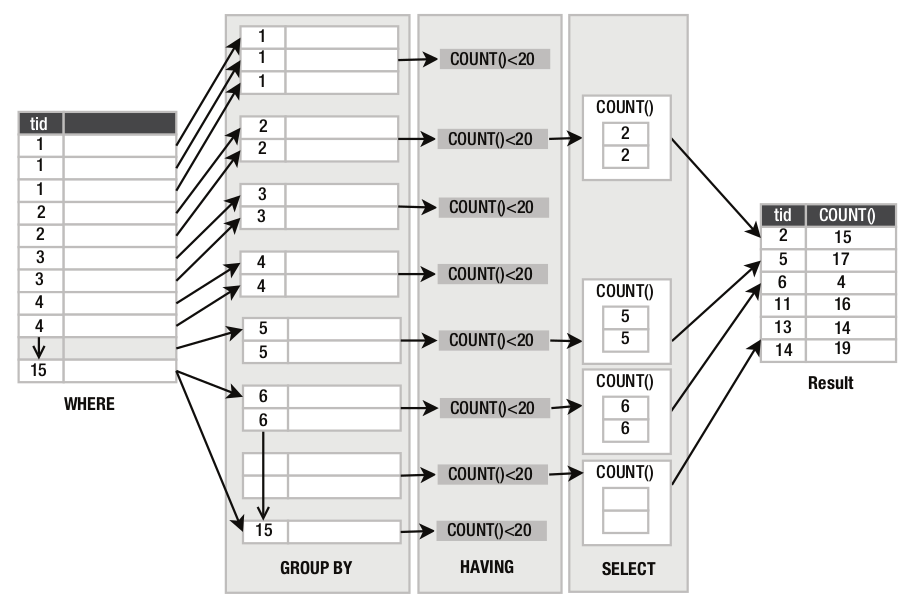
Resumindo, a sintaxe de uma consulta usando GROUP BY, HAVING e ORDER BY é: (Fonte: SQLite - HAVING Clause)
SELECT coluna1, coluna2, ...
FROM tabela1, tabela2, ...
WHERE [ condição ]
GROUP BY coluna1, coluna2, ...
HAVING [ condição ]
ORDER BY coluna1, coluna2, ...
Até o momento as consultas foram feitas a partir de uma única tabela, mas uma grande vantagem do comando SELECT é a possibilidade de usar os dados de duas ou mais tabelas para construir uma nova tabela.
Para usar mais de uma tabela em uma instrução SELECT, temos que seguir a seguinte sintaxe:
A cláusula FROM deve indicar cada uma das tabelas cujos dados serão usados
A cláusula WHERE deve conter uma “expressão de junção” definindo como as tabelas serão combinadas
Por exemplo, a tabela foods tem uma coluna food_types, e os valores dessa coluna correspondem aos valores da coluna id na tabela food_types.
sqlite> .schema CREATE TABLE episodes ( id integer primary key, season int, name text ); CREATE TABLE foods( id integer primary key, type_id integer, name text ); CREATE TABLE foods_episodes( food_id integer, episode_id integer ); CREATE TABLE food_types( id integer primary key, name text ); CREATE TABLE foods_copy (id int, type_id int, name text);
Portanto existe um “relacionamento” entre as duas tabelas. Qualquer valor na coluna foods.type_id deve ter um valor correspondente na coluna food_types.id, que por sinal é a “CHAVE PRIMÁRIA” (PRIMARY KEY) da tabela food_types.
Devido a essa correspondência a coluna food_types.id é chamada de “CHAVE ESTRANGEIRA” (FOREIGN KEY), ou seja, contém (ou se refere) a uma “CHAVE PRIMÁRIA” (PRIMARY KEY) de outra tabela.
Uma “CHAVE ESTRANGEIRA” (FOREIGN KEY) em uma tabela aponta para uma “CHAVE PRIMÁRIA” (PRIMARY KEY) em outra tabela.
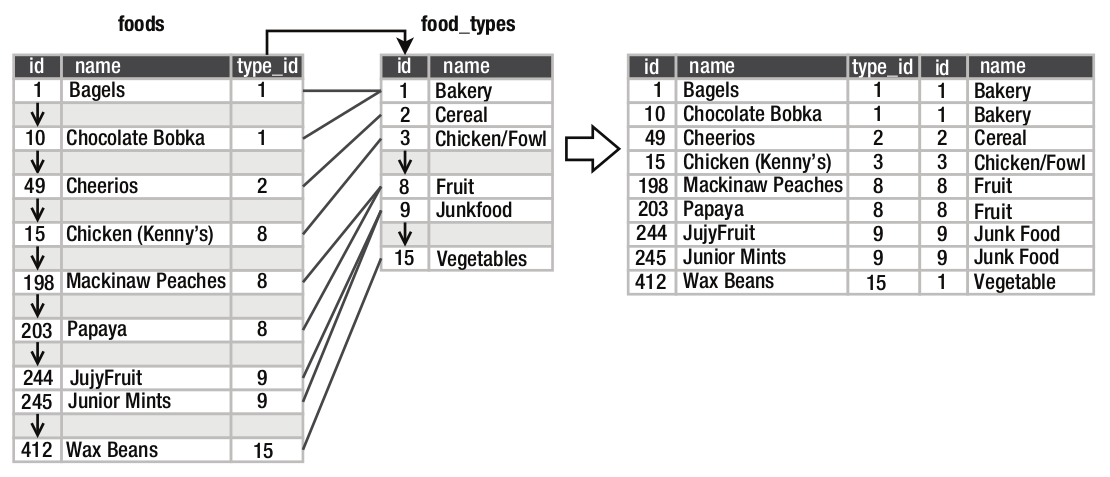
Esta correspondência pode ser usada para combinar as tabelas foods e food_types e produzir uma nova tabela com informações mais detalhadas tais como o nome do tipo de comida (food_types.name) para cada alimento na tabela foods.
Isso pode ser feito com os comandos:
sqlite> SELECT foods.name, food_types.name ...> FROM foods, food_types ...> WHERE foods.type_id = food_types.id; name name ---------- ---------- Bagels Bakery Bagels, ra Bakery . . . Veggie bur Vegetables Wax Beans Vegetables Cinnamon B Bakery Chocolate Bakery Blackberry Bakery Chocolate Bakery Cinnamon B Bakery Cinnamon B Bakery Chocolate Bakery Blackberry Bakery
Para limitar a exibição a 10 registros:
sqlite> .width 25 10 --Para definir a largura das colunas sqlite> SELECT foods.name, food_types.name ...> FROM foods, food_types ...> WHERE foods.type_id = food_types.id LIMIT 10; name name ------------------------- ---------- Bagels Bakery Bagels, raisin Bakery Bavarian Cream Pie Bakery Bear Claws Bakery Black and White cookies Bakery Bread (with nuts) Bakery Butterfingers Bakery Carrot Cake Bakery Chips Ahoy Cookies Bakery Chocolate Bobka Bakery
A cláusula “foods.type_id = food_type.id” é a “expressão de junção” que especifica como as tabelas serão reunidas.
Nota
Neste último exemplo foi usada uma nova notação para especificar as colunas na cláusula SELECT. Em vez de especificar apenas os nomes das colunas, foi utilizada a notação “nome_tabela.nome_coluna”.
A razão é que temos múltiplas tabelas no comando SELECT.
Para fazer a junção o banco de dados localiza as linhas correspondentes e para cada linha na primeira tabela o banco de dados localiza todas as linhas na segunda tabela para incluir na nova tabela. Portanto, neste exemplo a cláusula FROM criou uma nova tabela pela junção das linhas das duas tabelas originais conforme o diagrama da figura P.11.
Figura P.11. Diagrama esquemático da junção de duas tabelas. (Fonte: The Definitive Guide to SQLite, 2010)
O banco de dados SQLite suporta seis diferentes tipos junções (ou uniões): junção interna, junção externa, junção de produto cartesiano, left outer join, right outer join e full outer join. O exemplo anterior ilustra a “junção interna”, que é a mais comum.
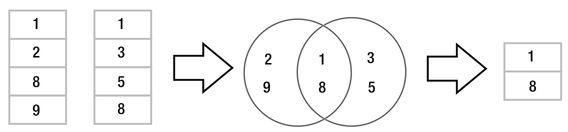
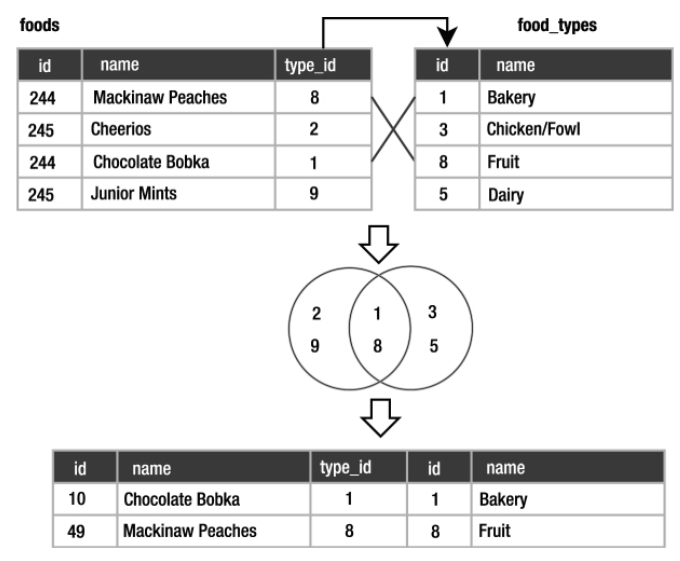
Uma junção interna utiliza uma operação da teoria dos conjuntos chamada “interseção” para identificar os elementos que existem em ambos os conjuntos.
A figura P.12 mostra que a interseção do conjunto {1, 2, 8, 9} com o conjunto {1, 3, 5, 8} é o conjunto {1, 8}.
Figura P.12. Diagrama esquemático da operação de interseção entre dois conjuntos. (Fonte: The Definitive Guide to SQLite, 2010)
Esse é o processo envolvido em uma junção interna, mas os conjuntos em uma junção são elementos comuns das colunas relacionadas. Considere que o conjunto da esquerda na figura P.12 representa os valores na coluna foods.type_id e o conjunto da direita representa os valores na coluna food_types.id. Após definidas as colunas correspondentes, uma junção interna encontra as linhas de ambos os lados que contêm valores semelhantes e as combina para formar as linhas da tabela resultante como mostra o diagrama da figura P.13.
Figura P.13. Diagrama esquemático da operação de junçao interna. (Fonte: The Definitive Guide to SQLite, 2010)
A atualização dos registros é feita com o comando UPDATE, o qual permite a modificação de uma ou mais colunas dentro de uma ou mais linhas em uma tabela.
Sintaxe do comando UPDATE:
UPDATE nome_da_tabela SET nome_da_coluna = expressão[, nome_da_coluna = expressão] [WHERE expressão]
A cláusula WHERE usa uma “expressão” (ou predicado) para identificar as linhas que devem ser modificadas.
Exemplo de uso:
sqlite> .width 5 5 25 sqlite> SELECT * FROM foods WHERE name LIKE 'Chocolate%'; id type_ name ----- ----- ------------------------- 10 1 Chocolate Bobka 11 1 Chocolate Eclairs 12 1 Chocolate Cream Pie 222 9 Chocolates, box of 223 9 Chocolate Chip Mint 224 9 Chocolate Covered Cherrie 415 1 Chocolate Bobka 417 1 Chocolate Bobka 421 1 Chocolate Bobka sqlite> UPDATE foods SET name='CHOCOLATE BOBKA' ...> WHERE name = 'Chocolate Bobka'; sqlite> SELECT * FROM foods WHERE name LIKE 'Chocolate%'; id type_ name ----- ----- ------------------------- 10 1 CHOCOLATE BOBKA 11 1 Chocolate Eclairs 12 1 Chocolate Cream Pie 222 9 Chocolates, box of 223 9 Chocolate Chip Mint 224 9 Chocolate Covered Cherrie 415 1 CHOCOLATE BOBKA 417 1 CHOCOLATE BOBKA 421 1 CHOCOLATE BOBKA sqlite>
Se a cláusula WHERE não for usada, o comando UPDATE modificará cada linha da tabela, desde que não viole nenhuma cláusula de integridade referencial fornecida durante a definição da tabela.
Por exemplo o comando seguinte gera um erro:
sqlite> UPDATE foods SET id = 11 WHERE name = 'CHOCOLATE BOBKA'; Error: UNIQUE constraint failed: foods.id
O banco de dados não faz a atualização do campo id pois apresenta a “restrição” (constraints) de ser uma PRIMARY KEY, e portanto deve ser única.
O comando DELETE, como seu nome indica, apaga as linhas de uma tabela com a seguinte sintaxe:
DELETE FROM nome_da_tabela [WHERE expressão]
A cláusula FROM nomeia a tabela a partir da qual as linhas serão apagadas. E a cláusula WHERE permite identificar as linhas que serão apagadas.
Por exemplo a declaração seguinte irá remover a linha com o id=420:
sqlite> SELECT * FROM foods; --Verificando os últimos registros . . . 415 1 CHOCOLATE BOBKA 416 1 Blackberry Bobka 417 1 CHOCOLATE BOBKA 418 1 Cinnamon Bobka 419 1 Cinnamon Bobka 420 NULL Cinnamon Bobka 421 1 CHOCOLATE BOBKA 422 1 Blackberry Bobka sqlite> DELETE FROM foods WHERE id=420; --Removendo o registro com id=420 sqlite> SELECT * FROM foods; --Verificando os últimos registros . . . 415 1 CHOCOLATE BOBKA 416 1 Blackberry Bobka 417 1 CHOCOLATE BOBKA 418 1 Cinnamon Bobka 419 1 Cinnamon Bobka 421 1 CHOCOLATE BOBKA 422 1 Blackberry Bobka
Removendo as linhas com name = 'CHOCOLATE BOBKA':
sqlite> SELECT * FROM foods WHERE name LIKE 'Chocolate%'; id type_ name ----- ----- ------------------------- 10 1 CHOCOLATE BOBKA 11 1 Chocolate Eclairs 12 1 Chocolate Cream Pie 222 9 Chocolates, box of 223 9 Chocolate Chip Mint 224 9 Chocolate Covered Cherrie 415 1 CHOCOLATE BOBKA 417 1 CHOCOLATE BOBKA 421 1 CHOCOLATE BOBKA sqlite> DELETE FROM foods WHERE name='CHOCOLATE BOBKA'; sqlite> SELECT * FROM foods WHERE name LIKE 'Chocolate%'; id type_ name ----- ----- ------------------------- 11 1 Chocolate Eclairs 12 1 Chocolate Cream Pie 222 9 Chocolates, box of 223 9 Chocolate Chip Mint 224 9 Chocolate Covered Cherrie
Uma transação trata uma série de modificações no banco de dados como se fosse uma única modificação. Ou seja, todas as modificações acontecem ou nenhuma acontece e se elas acontecerem, deverá ser de uma só vez.
Isso visa manter a “integridade do banco de dados” e é chamado de “princípio atômico de integridade do banco de dados.”
Um exemplo clássico que ilustra a importância de uma transação é uma transferência de dinheiro entre contas bancárias. Considere que um programa bancário está transferindo dinheiro de uma conta (1) para outra conta (2). O programa de transferência pode realizar essa operação de duas maneiras:
primeiro faz o crédito na conta 2 e em seguida faz o débito na conta 1
primeiro faz o débito na conta 1 e em seguida faz o crédito na conta 2
Em ambos os casos a transferência é um processo em “duas etapas”: uma inserção seguida de uma remoção, ou uma remoção seguida de uma inserção.
Agora imagine se durante a transferência o sistema rodando o banco de dados travar ou faltar energia e a segunda etapa da operação não se realizar?
No primeiro caso o dinheiro vai estar presente em ambas as contas, e no segundo caso o dinheiro vai desaparecer. Ou seja alguém vai sair perdendo em ambos os casos, e o banco de dados vai ficar em um estado “inconsistente”.
A questão fundamental neste caso é que: ambas as operações devem acontecer ou nenhuma delas deve acontecer. Essa é o princípio fundamental de uma transação.
O “escopo de uma transação” é definido pelo uso de 3 comandos: BEGIN, COMMIT e ROLLBACK.
O comando BEGIN inicia uma transação e todas as operações que seguem o comando BEGIN podem ser potencialmente desfeitas e serão efetivamente desfeitas se não for executado o comando COMMIT antes do fim da “seção”.
O comando COMMIT realiza efetivamente as ações pendentes deste o início da transação.
E da mesma forma o comando ROLLBACK cancela todas as operações pendentes desde o início da transação.
Uma transação é um escopo no qual “todas” as operaçoes são realizadas ou canceladas, “juntas”.
Exemplo de uma transação:
sqlite> BEGIN; sqlite> DELETE FROM foods; sqlite> ROLLBACK; sqlite> SELECT count(*) FROM foods; count(*) ---------- 417
Neste exemplo a transação foi iniciada com BEGIN, em seguida todas as linhas da tabela foods foram deletadas, mas em seguida essa operação foi cancelada com o comando ROLLBACK. E o comando SELECT mostra que a remoção não foi realizada.
Nota
Mas até agora não usamos os comandos BEGIN e COMMIT em nenhum dos exemplos desse tutorial e ainda assim as operações foram realizadas. Qual a razão?
Por padrão, cada comando SQL no SQLite é executado em sua própria transação, ou seja, se você não definir um escopo de transação com os comandos BEGIN...COMMIT/ROLLBACK, o SQLite envolverá “automaticamente” cada comando SQL em um BEGIN...COMMIT/ROLLBACK.
Se o comando for realizado com sucesso será executado um COMMIT, e ser houver um erro será cancelado com a execução do ROLLBACK.
Este modo de operação (transações implícitas) é chamado de “confirmação automática” (autocommit).
O SQLite executa automaticamente cada comando em sua própria transação e se não houver falhas são automaticamente implementadas (committed).